BERTopic - A Neural Topic Modelling framework for Guided Topic Extraction
1. Introduction
Topic Modelling is a powerful unsupervised technique to extract latent topics or themes in collections of documents. These topics help discover textual features in a corpus of documents and thus, help us cluster documents into more meaningful themes. However, conventional topic models like Latent Dirichlet Allocation and Non-Negative Matrix Factorization represent a document as a bag-of-words and model each document as a mixture of latent topics. A simple bag-of-words model represents a document as a bag of words, ignoring any grammar, semantics or word-order, but considering the frequency or multiplicity of words. Thus, conventional models based on this approach do not account for the context of words in a sentence, thus disregarding the context of the words. This may lead to an inaccurate representation of the documents. To improve on this, we use text embeddings that can generate contextual word and sentence vector representations. We can use transformers for this purpose. Transformers [1] are neural network architectures that can transform one sequence into another one with the help of two parts: encoders and decoders. Bidirectional Encoder Representations from Transformers (BERT) is a common technique used to to generate these representations with a semantic trait. These tools, when trained appropriately, can encode the meaning of texts such that texts with similar meaning are close to each other in a vector space. The below article describes a technique BERTopic[2], that groups documents into coherent clusters, based on these language-trained models.
2. Model Details
2.1. Document Embedding
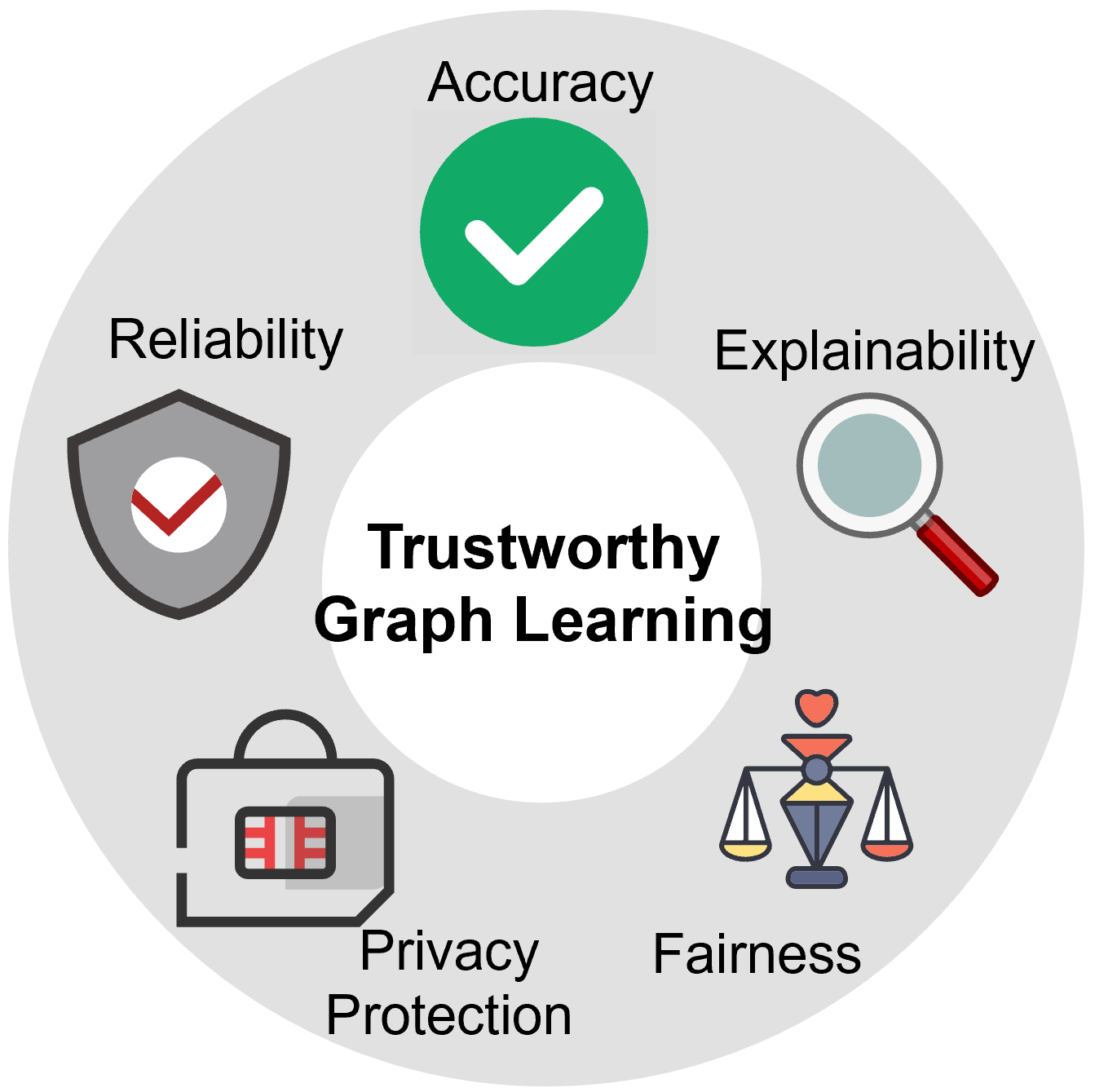
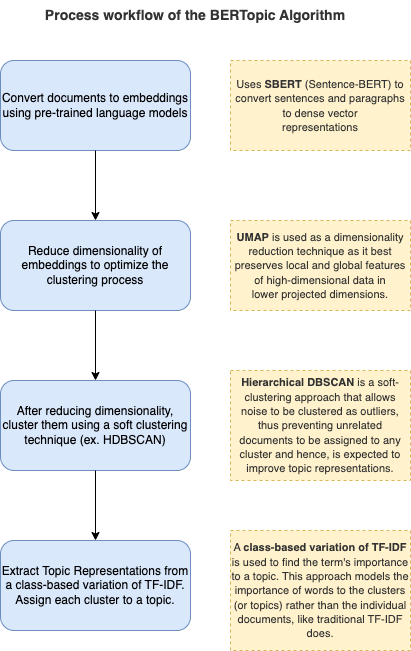
The Sentence-BERT or SBERT framework allows us to convert sentences to dense vector representations using pre-trained language models. The model is finetuned on semantic similarity so that we can use the embeddings to cluster semantically similar documents. This model is not directly used to generate topics, but helps us make semantically cohesive topics eventually.

While training SBERT as a classifier, we use the architecture shown above and optimize the cross-entropy loss.
Here,
However, for inference, we compute the cosine similarity between the two sentence embeddings

2.2. Dimensionality Reduction
The BERTopic framework suggests us to use UMAP [4] or Uniform Manifold Approximation and Projection for dimensionality reduction. Traditionally used techniques like PCA and t-SNE are popular dimensionality reduction techniques. However, UMAP is better at preserving the global and local features of the high-dimensional data when projected on to a lower dimensional space. Moreover, UMAP can be used across language models with differing dimensional space, thus eliminating any limitations of computational restrictions on embedding dimensions. UMAP also improves the efficiency of the DBSCAN model that is used to cluster documents in the next step. It helps both in the time complexity of the model and the accuracy of the clustering algorithm.
2.3. Document Clustering
After the document embeddings were projected on to a lower dimension using UMAP, the next step is to use a soft-clustering technique like DBSCAN to cluster the documents into clusters. The authors of BERTopic suggest using Hierarchical DBSCAN. HDBSCAN [5] is a hierarchical variation of DBSCAN which does not require the users to provide the number of output clusters as a parameter. It is a density-based clustering model that allows unrelated documents or noise to be grouped separately and not be assigned to any of the other clusters randomly. In other words, this model generates a complete density-based clustering hierarchy from which a simplified hierarchy composed only of the most significant clusters can be easily extracted.
\subsection {Topic Representation}
Each cluster derived from the last step is now assigned a topic in this last step i.e. We try to determine how each cluster is different from the other, on the basis of the cluster-word distribution.
For this, we use the concept of TF-IDF, just altered to a class-based system. Let us assume that a class
Here, the term-frequency (TF) is defined as the frequency
of term
When customized to a class-based system, the TF-IDF term looks like the following:
Here, the term-frequency component
This approach models the importance of the words within a cluster, instead of individual documents, thus generating topic-word distributions for each topic or cluster.
The final step is to iteratively merge the class-based TF-IDF
(c-TF-IDF) representation of the least common topic with its most similar topic/cluster, we can generate a number of topics as per the user-defined input parameter.
2.4. Implementation of BERTopic in Python
In this section, we show how to implement BERTopic on any given dataset using the simple package built from Python.
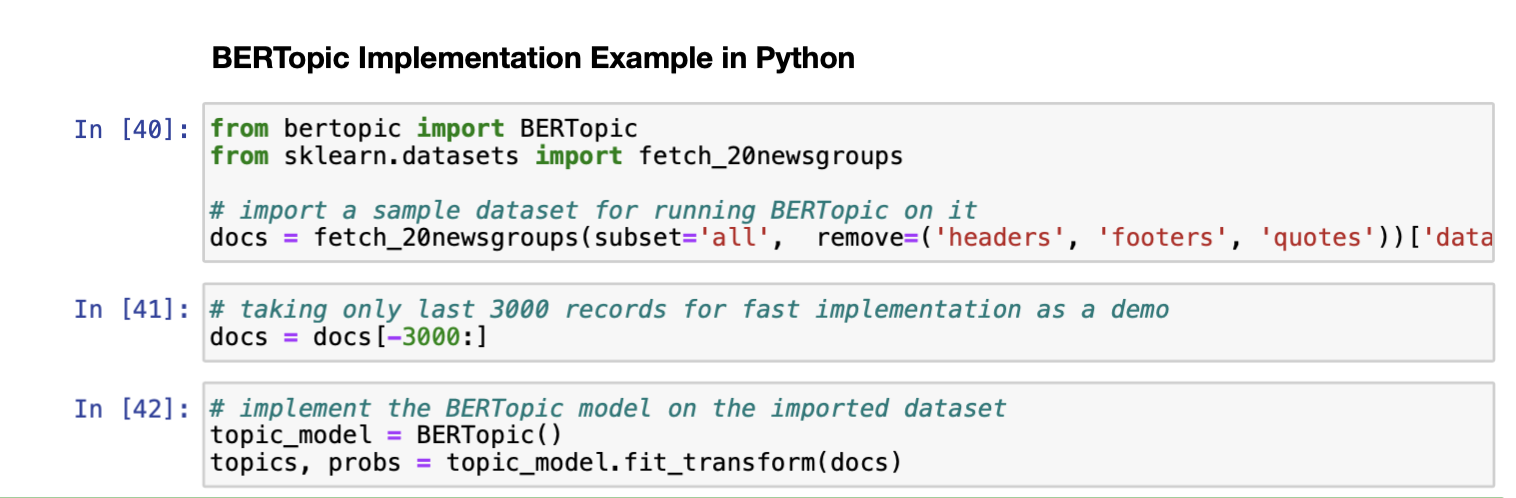
Please note that only the last 3000 documents were selected in the interest of run-time for this demo. This can affect the quality of the results as it changes the distribution of words and documents in the corpus. The next step is assess the results obtained from the model. The python library for the same provides simple commands to do the same.
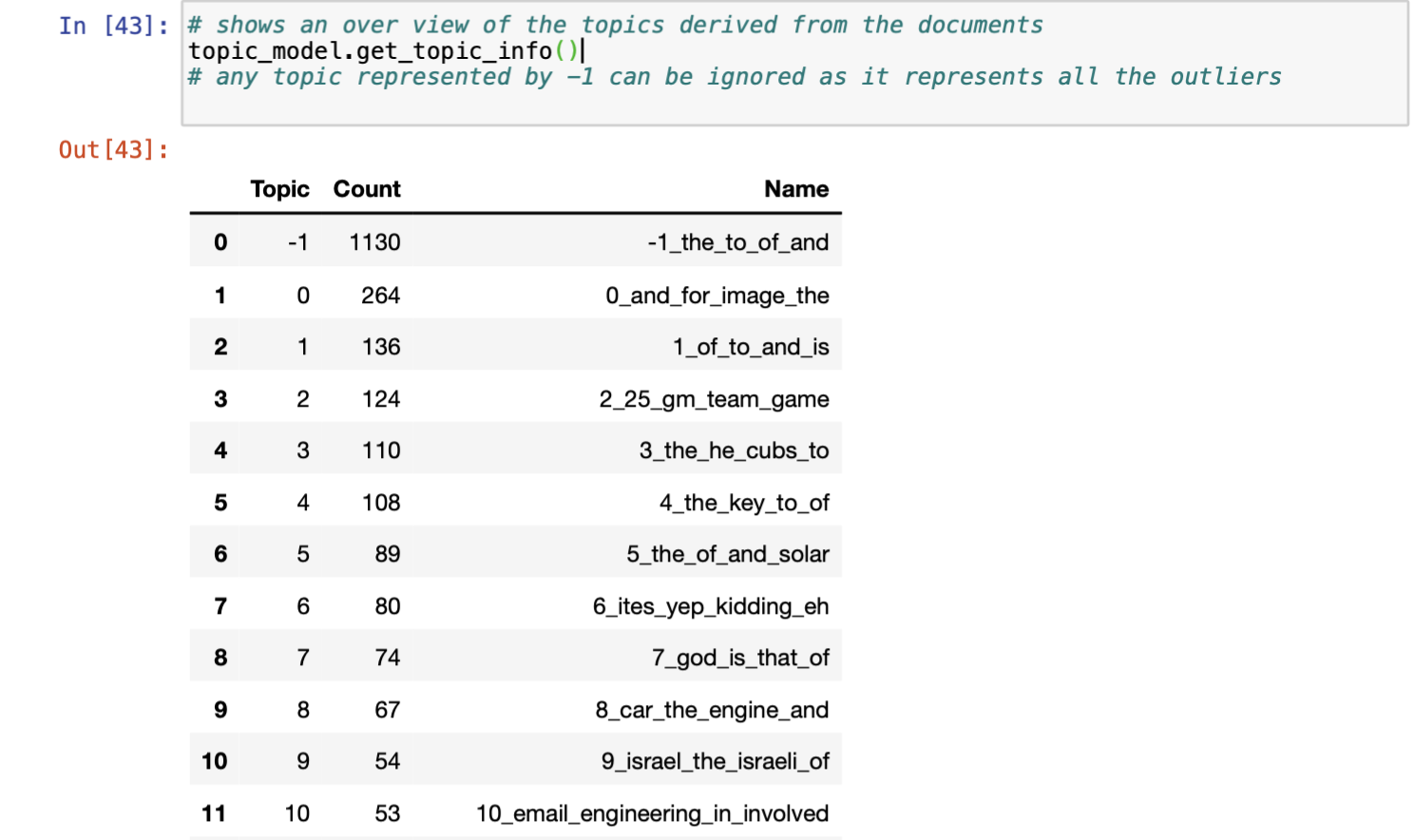
The above step gives us an overview of the topics generated by the model. In this example, 42 topics were generated. Topic labelled as -1 is a cluster of all the noisy outlier documents and can thus be ignored. We can also dive deeper into a particular topic. Below is an example of how the words are distributed within a given topic, here topic number 13. From the terms, it looks like a topic about memory storage devices like disk drives, floppy disks etc. The package also provides simple commands to visualize the results in different formats. Below is an example of bar charts that depict the term frequencies within each topic.

2.5. Improvements and Suggestions
Since the first step of the framework is to use a pre-trained model to obtain document embeddings, we can use various models to do the same. New advanced language models that show better results can be used to further improve the efficiency of the BERTopic framework for topic modelling.
Below is an example of how differnt embedding models can be used to embed the documents and words within the BERTopic implementation.

3. Dynamic Topic Modelling
An extension of the applications using BERTopic is Dynamic Topic Modelling which lends a temporal characteristic to topic modelling. Most conventional topic modelling frameworks are static, in the sense that they do not allow for sequentially organized documents to be modelled. Dynamic topic modelling factors in how these topics may have evolved over time and helps us show that through the topic representations.
This is done using the class-based TF-IDF (c-TF-IDF) where we assume that the temporal nature of the topics should not influence or affect the createion of global topics i.e. the same topic can appear ar different stages of the timeline, however, they may be represented differently or using different frequent terms.
Now, the first step is to generate global topics irrespective of the temporal nature. For this, the BERTopic model is fitted on the global corpus assuming there are no temporal factors to be accounted for. This gives us a sense of the global topic representation for a corpus.
Then, to create a local representation of each topic, we multiply the term-frequency of the documents at a time-step
This method allows for fast computation as it does not require us to embed clusters or documents. It also allows us to create topics by other metadata, like groups of authors or publications etc.
4. Conclusion
The above framework, BERTopic, covers for a lot of existing flaws of the conventional topic modelling frameworks. It allows for more semantically-cohesive topics to be made and does not force-fit noise or outlier documents into the existing clusters. It also leaes room for constant improvement on the basis of the pretrained language model used for document embedding. It also allows for ease of usability since the process is divided into isolated tasks of document embedding, clustering and creating topic representations.
5. References
- Vaswani A. et al. ‘‘Attention Is All You Need’’ (2017)
- Grootendorst M. "BERTopic: Neural topic modeling with a class-based TF-IDF procedure" (2022)
- Reimers N. et al. "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks" (2019)
- McInnes L. et al. "UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction" (2020)
- Campello R. et al. "Density-Based Clustering Based on Hierarchical Density Estimates" (2013)