Towards continual task learning in artificial neural networks
Towards continual task learning in artificial neural networks: current approaches and insights from neuroscience
Introduction & historical context
The innate capacity of humans and other animals to learn a diverse, and often interfering, range of knowledge and skills throughout their lifespan is a hallmark of natural intelligence, with obvious and irrefutable evolutionary motivations (Legg & Hutter 2007; Tenenbaum et al., 2011). In parallel, the ability of artificial neural networks (ANNs) to learn across a range of tasks and domains, combining and re-using learned representations where required, is a clear goal of artificial intelligence. This capacity, widely described as continual learning, has become a prolific subfield of research in machine learning (Hadsell et al., 2020). Despite the numerous successes of deep learning in recent years, across domains ranging from image recognition to machine translation (Krizhevsky et al., 2012; Vaswani et al., 2017), such continual task learning has proved challenging. Neural networks trained on multiple tasks in sequence with stochastic gradient descent often suffer from representational interference, whereby the learned weights for a given task effectively overwrite those of previous tasks in a process termed catastrophic forgetting (French, 1999). This represents a major impediment to the development of more generalised artificial learning systems, capable of accumulating knowledge over time and task space, in a manner analogous to humans (Hinton et al., 1986; Hassabis et al., 2017; Marblestone et al., 2016).
A proliferation of research seeking to alleviate the catastrophic forgetting problem has emerged in recent years, motivated by the requirement for machine learning pipelines to accumulate and analyse vast data streams in real-time (Parisi et al., 2019). Despite significant progress being made through such research, both in theory and application, the sub-field of continual learning research is vast, and therefore benefits from clarification and unifying critical appraisal. Simple categorisation of these approaches according to network architecture, training paradigm, and regularisation proves useful in structuring the literature of this increasingly important sub-field. Furthermore, many existing approaches to alleviating catastrophic forgetting in neural networks draw inspiration from neuroscience (Hassabis et al., 2017). This review will address both of these issues, providing a broad critical appraisal of current approaches to continual learning, while interrogating the extent to which insight might be provided by the rich literature of learning and memory in neuroscience.
Architectural considerations:
The influence of network architecture on task performance has been widely described in machine learning (LeCun et al., 2015), and represents a fruitful area of continual learning research (Parisi et al., 2019). In particular, attention has focussed on network architectures which dynamically reconfigure in response to increasing training data availability, primarily by recruiting the training of additional neural network units or layers.
Progressive neural networks are one such example, where a dynamically expanding neural network architecture is employed (Rusu et al., 2016). For training on each subsequent task, this model recruits additional neural networks which are trained on these tasks, while transfer of learned knowledge across tasks is facilitated by learned ‘lateral’ connections between the constituent networks (Figure 1A). Together, this alleviates catastrophic forgetting in a range of reinforcement learning benchmarks, such as Atari games, and compares favourably with baseline methods which leverage pre-training or fine-tuning of model parameters (Figure 1B,C). Despite the empirical successes of progressive networks, an obvious conceptual limitation is that the number of network parameters grows with the number of tasks experienced. For sequential task training (on n tasks), the broader applicability of this method, as n tends to infinity, remains unclear.

Figure 1. A) Schematic of the Progressive neural network architecture, where each of the three columns represents a constituent neural network instantiated to solve a given task. Concretely, the first two columns represent networks trained on tasks 1 and 2, respectively. The third column on the right represents a third network added to solve a novel task, and can draw on previously learned features via lateral connections between the networks (as indicated by the arrows). B) An example task domain (adapted from Rusu et al., 2016), in which a range of 3-dimensional labyrinths are navigated to attain reward. The structural diversity of these environments makes them an ideal test of continual task learning. C) Atari 2600 games similarly offer a paradigm for testing continual learning, but with a richer and more complex set of tasks and environments.
An alternative approach was proposed by Draelos et al. (2017), which takes direct inspiration from hippocampal neurogenesis, a well-described phenomenon from neuroscience in which new neurons are formed in adulthood, raising intriguing questions of learning and plasticity in both natural and artificial intelligence settings (Amione et al., 2014). The method proposed in this paper, termed neurogenesis deep learning, is conceptually similar to that of progressive neural networks, but in this instance involves additional neurons in deep neural network layers being recruited as the network is trained on subsequent tasks. Draelos et al. implement this as an autoencoder trained on the MNIST dataset of handwritten digits. As a greater range of digits is added incrementally to the training distribution, units are added in parallel to the autoencoder, thereby giving rise to the ‘neurogenesis’ in this dynamic network architecture. The autoencoder network in this instance preserves weights associated with previously learned tasks using a form of replay, while the reconstruction error provides an indication of how well representations of previously learned digits are preserved across learning of subsequent digits (that is, subsequent task learning). This paper presents an elegant idea for mitigating catastrophic forgetting, but further experiments are required to fully appraise its potential. For instance, the incremental training data used in this paper is solely in the form of discrete, one-hot categories, rather than the more challenging (and more naturalistic) scenario of novel data accumulating gradually, or without clear boundaries.
Both of the approaches discussed so far have involved dynamic network architectures, but nonetheless ones in which networks or units are recruited and incorporated in response to subsequent tasks. An alternative method has been advanced by Cortes et al. (2016), in which no network architecture is explicitly encoded. Instead, the proposed AdaNet algorithm adaptively selects both the optimal network architecture and weights for the given task. When tested on binary classification tasks drawn from the popular CIFAR-10 image recognition dataset, this approach performed well, with the algorithm automatically learning appropriate network architectures for the given task. Although AdaNet has not been tested exhaustively in the context of continual learning, it represents an appealing method of dynamically reconfiguring the network to mitigate catastrophic forgetting with subsequent tasks.
Overall, some combination of these approaches – a dynamic network architecture and an algorithm for automatically inferring the optimal architecture for newly encountered tasks – is likely to offer potential solutions to continual learning.
Regularisation:
Imposing constraints on the neural network weight updates is another major area of continual learning research. Such regularisation approaches have proved popular in recent years, and many derive inspiration from models of memory consolidation in theoretical neuroscience (Fusi et al., 2005; Losonczy et al., 2008).
- Learning without forgetting: Li & Hoiem, 2016
Learning without forgetting (LwF) is one such proposed regularisation method for continual learning (Li & Hoiem, 2016), and draws on knowledge distillation (Hinton et al., 2015). Proposed by Hinton and colleagues, knowledge distillation is a technique in which the learned knowledge from a large, regularised model (or ensemble of models) is distilled into a model with many fewer parameters (the details of this technique, however, are beyond the scope of this review). This concept was subsequently employed in the LwF algorithm to provide a form of functional regularisation, whereby the weights of the network trained on previous tasks or training data are enforced to remain similar to the weights of the new network trained on novel tasks. Informally, LwF aims to effectively take a representation of the network before training on new tasks. In Li & Hoiem, this was implemented as a convolutional neural network, in which only novel task data was used to train the network, while the 'snapshot' of the prior network weights preserved good performance on previous tasks. This approach has garnered significant attention in recent years, and offers a novel perspective on the use of knowledge distillation techniques in alleviating catastrophic forgetting. However, Learning without Forgetting has some notable limitations. Firstly, it is highly influenced by task history, and is thus susceptible to forming sub-optimal representations for novel tasks. Indeed, balancing stability of existing representations with the plasticity required to efficiently learn new ones is a major unresolved topic of research in continual learning. A further limitation of LwF is that, due to the nature of the distillation protocol, training time for each subsequent task increases linearly with the number of tasks previously learned. For broad applicability, this practically limits the capacity of this technique to handle pipelines of training data for which novel tasks are encountered regularly.
- Elastic weight consolidation: Kirkpatrick et al., 2017
In recent years, one of the most prominent regularisation approaches to prevent catastrophic forgetting is that of elastic weight consolidation (EWC) (Kirkpatrick et al., 2017). EWC, which is suitable for supervised and reinforcement learning paradigms, takes direct inspiration from neuroscience, where synaptic consolidation is thought to preserve sequential task performance by consolidating the most important features of previously encountered tasks (Yang et al., 2009). Intuitively, EWC works by slowing learning of the network weights which are most relevant for solving previously encountered tasks. This is achieved by applying a quadratic penalty to the difference between the parameters of the prior and current network weights, with the objective of preserving or consolidating the most task-relevant weights. It is this quadratic penalty, with its ‘elastic’ preservation of existing network weights, which takes inspiration from synaptic consolidation in neuroscience, and is schematically represented in Figure 2A. More formally, the loss function of EWC, L(θ), is given by:

Where θ represents the parameters of the network, L_B(θ) represents the loss for task B, λ is a hyperparameter indicating the relative importance of previously encountered tasks compared to new tasks, F is the Fisher information matrix, and finally θA* represents the trainable parameters of the network important for solving previously encountered tasks. Intuitively, this loss function can be understood as penalising large differences between previous and current network weights (the term within the brackets). In EWC, the Fisher information matrix is used to give an estimation of the importance of weights for solving tasks, by using an importance weighting proportional to the diagonal of the Fisher information metric over the old parameters for the previous task. While conceptually elegant, this presents a notable limitation of EWC: exact computation of this Fisher diagonal has complexity linear with the number of outputs, limiting the applicability of this method to low-dimensional output spaces.
Empirically, EWC performs well on supervised and reinforcement learning tasks, such as MNIST digit classification and sequential Atari 2600 games, respectively. However, the suitability of the quadratic penalty term (which is only derived for the two-task case in the original paper) has been questioned for cases of multi-task learning (Huszár, 2018). Additionally, building on the strong empirical results presented in the paper, Kemker et al. (2018) demonstrated in further experiments that EWC fails to learn new classes incrementally in response to accumulating training data (Figure 2C). Overall, EWC is a promising method for alleviating catastrophic forgetting, but several details regarding its broader applicability (and theoretical underpinning) remain unresolved.

Figure 2. A) Schematic of the analogy between synaptic consolidation (left) and the regularisation of EWC (right), in which network weights important for solving previous tasks are preserved in an ‘elastic’ manner. Adapted from Hassabis et al., 2017. B) Schematic showing the parameter spaces of tasks A and B, for which EWC finds the optimal balance of weights for preserving performance of task A after training on task B. Unlike other regularisation approaches (such as L2 regularisation, as depicted), EWC does so by explicitly calculating the importance of weights in the network for solving a given task. Adapted from Kirkpatrick et al., 2017. C) Following on from the impressive empirical results described in the original paper, Kemker et al. provided more thorough testing of EWC. Here, they report that this method is unable to learn new task classes incrementally (in this case, adding new MNIST digit classes incrementally).
- Synaptic intelligence: Zenke et al., 2017
An approach closely related to EWC is that of synaptic intelligence (Zenke et al., 2017). In this method, however, individual synapses (the connections between neurons or units) estimate their importance in solving a given task. Such intelligent synapses can then be preserved for subsequent tasks by penalising weight updates, thereby mitigating catastrophic forgetting of previously learned tasks. Intuitively, synaptic intelligence can be considered a mechanism of anchoring network weights relevant for previous tasks to their existing values, and decelerating updates of these weights to prevent over-writing of previous task performance.
In summary, numerous regularisation methods have been developed to aid continual learning. By modulating gradient-based weight updates, these methods aim to preserve the performance of the model across multiple tasks trained in sequence. Many such regularisation methods have garnered interest from the research community, both due to both their theoretical appeal and strong empirical validation. Ultimately, however, none of these approaches has offered a comprehensive solution to the continual learning problem, and it is likely that a deeper understanding of credit assignment within neural networks will drive this research further.
Training regimes:
Beyond the model itself, the training regime employed is critical to sequential task performance, and represents a rich avenue of continual learning research. Although numerous training paradigms have been described, this review will focus on those most directly developed to alleviate catastrophic forgetting:
- Transfer learning:
Historically, limitations of dataset size have motivated the study of transfer learning for machine learning systems, with the aim of initially training ANNs on large datasets before transferring the trained network parameters to other tasks (Bengio et al., 2012; Higgins et al., 2016). The recent successes of transfer learning in fields such as computer vision and natural language processing are well-documented. For instance, Yosinski et al. (2014) demonstrated the efficacy of transfer learning for computer vision in a range of benchmarking datasets. It was then found that subsequent layers in the hierarchy of the neural network display representational features which are reminiscent of human visual cognition (such as edge detection in lower layers and image-specific feature detection in higher layers).
Successes of transfer learning in few-shot learning paradigms, which aim to perform well upon first presentation of a novel task, have been well-described in recent years (Palatucci et al., 2009; Vinyals et al., 2016). However, translation of this potential into alleviating catastrophic forgetting has proved more challenging. One of the earliest attempts to leverage transfer for continual learning was implemented in the form of a hierarchical neural network, termed CHILD, trained to solve increasingly challenging reinforcement learning problems (Ring, 1997). This model was not only capable of learning to solve complex tasks, but also demonstrated a degree of continual learning – after learning nine task structures, the agent could still successfully perform the first task when returned to it. The impressive (and perhaps overlooked) performance of CHILD draws on two main principles: firstly, transfer of previously learned knowledge to novel tasks; secondly, incremental addition of network units as more tasks are learned. In many ways, this model serves as a precursor of progressive neural networks (Rusu et al., 2016), and offers an appealing account of transfer learning in aiding continual task learning.
- Curriculum learning:
In parallel to this, curriculum learning has gained attention of improving continual learning capacities in ANNs (Bengio et al., 2009; Graves et al., 2017). Broadly, curriculum learning can be defined as the phenomenon by which both natural and artificial intelligence agents learn more efficiently when the training dataset contains some inherent structure, and when exemplars provided to the learning system are organised in a meaningful way (for instance, progressing in difficulty) (Bengio et al., 2009). When trained on datasets such as MNIST, curriculum learning both accelerates the learning process (as measured by time or training steps to reach the global minimum – that is, the optimum of the model) and helps prevent catastrophic forgetting (Bengio et al., 2009). However, one limitation of curriculum learning in ANNs is the assumption that task difficulty can be represented in a linear and uniform manner (often described as a ‘single axis of difficulty’), disregarding the nuances of each task structure. Nevertheless, curriculum learning is a promising, and underexplored, avenue of research for better continual learning performance in neural networks.
- Generative replay: Shin et al. (2017)
The neural phenomenon of hippocampal (or, more generally, memory) replay has recently garnered attention with respect to the design of ANNs (Shin et al., 2017; Kemker & Kanan, 2018). Shin et al. (2017) designed the model most obviously inspired by hippocampal replay, with a training regime termed Deep Generative Replay. This comprises a generative model and a task-directed model, the former of which is used to generate representative data from previous tasks, from which a sample is selected and interspersed with the dataset of the new task. In this way, the model mimics hippocampal replay, drawing on statistical regularities from previous experiences when completing novel tasks (Liu et al., 2019). This approach, which shares some conceptual similarities to the model proposed by Draelos et al. (2017), displays a substantial improvement in continual learning compared to complexity-matched models lacking replay.
Several other implementations of replay in neural networks have also been described, including a straightforward experience replay buffer of all prior events for a reinforcement learning agent (Rolnick et al., 2018). This method, called CLEAR, attempts to address the stability-plasticity tradeoff of sequential task learning, using off-policy learning and replay-based behavioural cloning to enhance stability, while maintaining plasticity via on-policy learning. This outperforms existing deep reinforcement learning approaches with respect to catastrophic forgetting, but might prove unsuitable in cases where storage of a complete memory buffer is intractable.

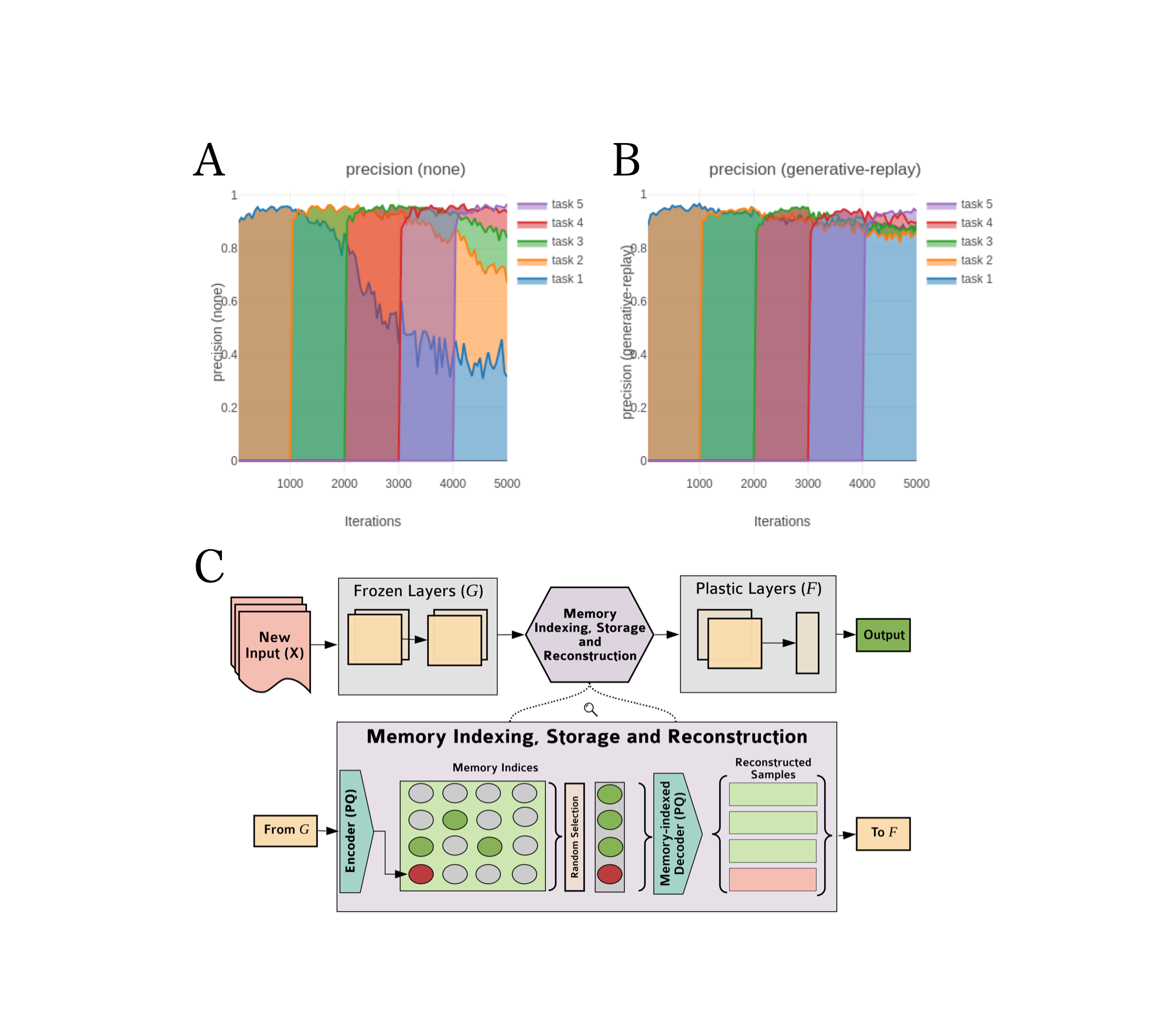
Figure 3. Sub-panels A and B demonstrate the efficacy of deep generative replay in alleviating catastrophic forgetting. A) When a neural network is trained on sequential tasks (in this case, from the permuted MNIST dataset) with vanilla gradient descent, catastrophic forgetting of previous task performance occurs due to overwriting of the weights associated with these prior tasks. As multiple tasks in sequence are encountered, performance on previous tasks can decrease dramatically, as the network weights optimised for these prior tasks are ‘catastrophically forgotten’. B) Conversely, when the network is trained with deep generative replay, continual learning across tasks is much improved. By sampling training data from previous tasks and interleaving this with the current task, this method enables multiple tasks to be learned in sequence with the same network, without catastrophic forgetting of earlier task performance (adapted from a PyTorch implementation of deep generative replay). C) Schematic of the REMIND model, which proposes the replay of compressed data representations in a more biologically plausible framework. REMIND takes an input image (denoted X in the schematic), and compresses this into low-dimensional tensor representations of that training data by passing it through the neural network layers labelled G. These compressed representations can then be efficiently stored in memory (as shown by the lower box in the schematic), and indexed for replay as required. The compressed tensor representations can be reconstructed by the neural network layers labelled F, and interleaved with current training data. A more comprehensive description can be found here.
- REMIND: Hayes et al. (2019)
Drawing on the successes of replay in alleviating catastrophic forgetting, Hayes et al. (2019) proposed a novel method which more accurately reflects the role of memory replay as described by modern neuroscience, implemented as a convolutional neural network. Standard replay approaches for CNNs rely on presenting raw pixel input from previously encountered data interleaved with novel data. Although effective, this approach is both biologically implausible and memory-intensive. By contrast, the REMIND (replay using memory indexing) algorithm proposed in this paper replays a compressed representation of previously encountered training data, thereby enabling efficient replay and online training. This approach is directly inspired by hippocampal indexing theory (Teyler & Rudy, 2007), and proposes a solution to the issue with prior replay implementations of having to store raw training data from previous tasks. In REMIND, this compression of input data is achieved using layers of the neural network, where the raw input data is compressed into a lower-dimensional tensor representation (for instance, in the context of CNNs, a feature map) for replay (see Figure 3C). Hayes et al. implement this using product quantization, a technique for compressing data which has a significantly lower reconstruction error compared to other methods (the details of product quantization are beyond the scope of this review, but see Jegou et al., 2010 for a comprehensive account). This compression proves highly effective in maximising memory efficiency: REMIND can store 1 million compressed representations compared to just 20,000 when raw data input is stored in alternative models, matched for memory capacity. Empirically, replay of compressed training data was shown to confer strong benefits, whereby REMIND outperforms constraint-matched methods on incremental class learning tasks derived from the ImageNet dataset.
Can inspiration be drawn from neuroscience?
Neuroscience (in particular, cognitive neuroscience) and artificial intelligence have long been intertwined both in aetiology and research methodologies (Hassabis et al., 2017; Hinton et al., 1986), and this intersection has already inspired numerous approaches to continual learning research. Many of the methods described previously in this review draw inspiration from neuroscience, either implicitly or explicitly (for instance, generative replay, REMIND algorithm, and transfer learning are all conceptually indebted to decades of neuroscience research).
One line of justification for this approach is that there are studies demonstrating a phenomenon analogous to catastrophic forgetting in humans, suggesting that a shared mechanistic framework might underlie continual learning (and its inherent limitations) in both humans and ANNs (Pallier et al., 2003; Mareschal et al., 2007). The first of these studies, Pallier et al. (2003), examined language acquisition and overwriting in Korean-born subjects whose functional mother tongue was French (due to being adopted before the age of 8), and had no conscious knowledge of the Korean language, as verified by behavioural testing. Functional neuroimaging (fMRI) demonstrated that the Korean-born francophone subjects displayed no greater (cortical) response to the Korean language in the setting of passive listening compared to French subjects with no exposure to Korean. This was interpreted as a form of over-writing, or catastrophic forgetting, of the first language by the second. The significance of these results is unclear, particularly given the limited literature on human catastrophic forgetting, but represents an interesting mandate for the use of cognitive neuroscience as a source of inspiration for continual learning research.
Replay in humans and neural networks:
From the perspective of neuroscience, several mechanistic features underpinning human continual learning have been dissected, such as memory replay (perhaps as a means of transferring learned knowledge from short-term to long-term storage), curriculum and transfer learning paradigms, structural plasticity, and the integration of multiple sensory modalities to provide rich sensory context for memories (Parisi et al., 2019).
One phenomenon widely considered to contribute to continual learning is memory replay or hippocampal replay, defined as the re-activation (hence, replay) of patterns of activity in hippocampal neurons during states of slow-wave sleep and passive, resting awake (Skaggs et al., 1996; Schönauer et al., 2017; Dave & Margoliash 2000; Rudoy et al., 2009). Such replay episodes are thought to provide additional trials serving to rehearse task learning and generalise knowledge during so-called ‘offline’ learning, and were first identified by recording hallmarks of brain activity during learning and mapping these onto covarying activity patterns identified during sleep (Rasch et al., 2018). An elegant demonstration of this phenomenon in humans was provided by Rudoy et al. (2009), whereby subjects learned the position of arbitrary objects on a computer screen, with each object presented in association with a unique and characteristic sound. The participants then slept for a short period of time, with electroencephalography (EEG) used to identify different stages of sleep. During slow-wave sleep, the characteristic sounds for half of the objects were played at an audible but unobtrusive volume. It was found that the participants subsequently recalled the positions of these sound-consolidated objects with greater accuracy. Replay approaches in machine learning have already proved fruitful, and studies such as these from neuroscience only serve to further motivate replay as a topic of continual learning research.
Replay, as well as the lesser-understood hippocampal pre-play (whereby hippocampal neurons display what is thought to represent simulated activity which can be mapped onto future environments) might aid continual learning through this ‘offline’ consolidation (Dragoi & Tonegawa, 2011; Bendor & Spiers, 2016). Although the mechanism is incompletely described, it has been proposed that replay could contribute to continual learning by promoting the consolidation of previous task knowledge (Ólafsdóttir et al., 2018). In some ways, this can be considered analogous to pre-training neural networks with task-relevant data, and might prove an interesting research avenue for continual learning.
Indeed, the value of neuroscience-inspired research was recently underlined by a study from van de Ven et al. (2020). Here, a more biologically plausible form of replay was implemented, whereby instead of storing previous task data, a learned generative model was trained to replay internal, compressed representations of that data. These internal representations for replay were then interleaved with current training data in a context-dependent manner, modulated by feedback connections. This approach also overcomes a potential issue with existing replay methods in machine learning – cases where storing previously encountered data is not permissable due to safety or privacy concerns. Replay of compressed representations, or replay in conjunction with some form of federated learning, might offer a solution in these instances.
Complementary learning systems for continual learning:
Complementary learning systems (CLS) theory, first advanced by McClelland et al. (1995) and recently updated by Kumaran et al. (2016), delineates two distinct structural and functional circuits underlying human learning (McClelland et al., 1995; Kumaran et al., 2016; O’Reilly et al., 2004; Girardeau et al., 2009). The hippocampus serves as the substrate for short-term memory and the rapid, ‘online’ learning of knowledge relevant to the present task; in parallel, the neocortex mediates long-term, generalised memories, structured over experience. Transfer of knowledge from the former to the latter occurs with replay, and it is intuitive that the catastrophic forgetting of previously learned knowledge in machine learning systems could be mitigated to some extent by such complementary learning systems. This has proved an influential theory in neuroscience, offering an account of the mechanisms by which humans accumulate task performance over time, and has started to provide ideas for how complementary learning systems might aid continual learning in artificial agents.
Transfer & curriculum learning:
Furthermore, the learning strategies employed by humans, of which transfer learning and curriculum learning have come into recent focus, are themselves likely to contribute further to continual learning (Barnett & Ceci, 2002; Holyoak & Thagard, 1997). Humans are capable of transferring knowledge between domains with minimal interference, and this capability derives from both continual task learning and generalisation of previously learned knowledge. A human learning to play tennis, for instance, can generalise some features of this task learning to a different racquet sport (Goode & Magill, 1986). Such transfer learning is poorly understood at the level of neural computations, and has perhaps been neglected by the neuroscience research community until recently, when attempts to endow artificial agents with these abilities has re-focussed attention on the mechanisms underpinning transfer learning in humans (Weiss et al., 2016).
Attempts to explain this abstract transfer of generalised knowledge in humans have themselves recapitulated many features of continual learning (Doumas et al., 2008; Barnett & Ceci, 2002; Pan & Yang, 2010; Holyoak & Thagard, 1997). For instance, Doumas et al. (2008) proposed that this is achieved by the neural encoding of relational information between objects comprising a sensory environment. Critically, such relational information would be invariant to nuances and specific features in these objects, and this could aid continual learning by providing a generalised task learning framework. Although the neural coding for such a relational framework has not yet been elicited, an intriguing recent paper by Constantinescu et al. (2016) proposed abstract concepts are encoded by grid cells in the human entorhinal cortex in a similar way to maps of physical space. Just as replay and memory consolidation have already led approaches to continual learning, such research might inspire novel approaches to alleviating catastrophic forgetting.
A related, and perhaps lesser-studied, learning paradigm is that of curriculum learning (Bengio et al., 2009; Elman, 1993). Intuitively, curriculum learning states that agents (both natural and artificial) learn more effectively when learning examples are structured and presented in a meaningful manner. The most obvious instantiation of this is to increase the difficulty of the learning rules throughout the sequence of examples presented; indeed, this is consistent with the structure of most human educational programmes (Krueger & Dayan, 2009; Goldman & Kearns, 1995; Khan et al., 2011). It has been appreciated for some time that this form of non-random learning programme aids human continual learning (Elman, 1993; Krueger & Dayan, 2009); however, the theoretical underpinnings of this are only starting to be elicited. Curriculum learning has the potential to enhance continual learning in neural networks by providing more structured training regimes, which emphasise the features of the training dataset which are most relevant to the tasks. Ultimately, however, more work is required to explore the promise of this.
Multi-sensory integration & attention:
It has been appreciated for some time in the field of cognitive neuroscience that humans receive a stream of rich multi-sensory input from the environment, and that the ability to integrate this information into a multi-modal representation is critical for cognitive functions ranging from reasoning to memory (Spence, 2010; Spence, 2014; Stein & Meredith, 1993; Stein et al., 2014). By enriching the context and representation of individual memories, multi-sensory integration is thought to aid human continual learning.
There is also evidence that attention is a cognitive process contributing to continual learning in humans (Flesch et al., 2018). Here, when the task learning curriculum was designed in a manner permitting greater attention (namely, with tasks organised in blocks for training, rather than ‘interleaved’ task training), continual learning of the task in the (human) subjects was enhanced. Even if optimal training regimes differ across biological and artificial agents, this underlines the importance of curriculum and attention in addressing catastrophic forgetting.
Future perspective: bridging neuroscience and machine learning to inspire continual learning research:
The inherent efficacy of human continual learning and its cognitive substrates is perhaps most impressive when contrasted with the current inability to endow AI agents with similar properties. With a projected increase in global data generation from 16 zettabytes annually in 2018 to over 160 zettabytes annually by 2025 (and the consequent impossibility of comprehensive storage), there is a clear motivation for developing machine learning systems capable of continual learning in a manner analogous to humans (IDC White Paper, 2017; Tenenbaum et al., 2011).
The super-human performance of deep reinforcement learning agents on a range of complex learning tasks, from Atari 2600 video games to chess, has been well-publicised in recent years (Mnih et al., 2015; Mnih et al., 2016; Silver et al., 2018; Kasparov, 2018; LeCun et al., 2015). However, these successes conceal a profound limitation of such machine learning systems: an inability to sustain performance when trained sequentially over a range of tasks. Traditionally, approaches to the issue of catastrophic forgetting have focussed on training regime, and often remain tangential to the cause of such forgetting. In the future, bridging the conceptual gap between continual learning research and the rich literature of learning and memory in neuroscience might prove fruitful, as motivated by several of the examples already discussed in this review.
Parallels of CLS theory in machine learning systems:
For example, with respect to CLS theory, biologically inspired neural network architectures involving two different network parameters (a ‘plastic’ parameter for slow-changing information, and a rapidly updating parameter) have existed for decades (Hinton & Plaut, 1987). Indeed, these networks outperformed state-of-the-art ANNs in continual learning-related tasks at their time of development. When considered from the perspective of CLS theory, this suggests that the parallel and complementary functions of the hippocampus and neocortex in human memory contribute to continual learning.
More recent models, such as the Differentiable Neural Computer (DNC), also support the view that having complementary memory systems supports continual learning (Graves et al., 2016). The DNC architecture consists of an artificial neural network and an external memory matrix, to which the network has access to store and manipulate data structures (broadly analogous to random-access memory). As such, a DNC can be interpreted as having ‘short-term’ and ‘long-term’ memory proxies, and the capacity to relay information between them. This model is capable of solving complex RL problems, and answering natural language questions constructed to mimic reasoning, lending further support to the contribution of complementary learning systems in human continual learning. The true potential of such approaches, however, remains unclear, and requires further investigation.
Emerging significance of multi-sensory integration & attention in artificial intelligence agents for continual learning:
In the context of continual learning in machine learning, multi-sensory integration (often called multi-modal integration in this context) has an obvious benefit of conferring additional information from different modalities when the environment is uncertain or has high entropy. Indeed, multi-modal machine learning has demonstrated efficacy in a range of task learning paradigms, such as lip reading, where the presence of both audio (phoneme) and visual (viseme) information improves performance compared to a uni-sensory training approach (Ngiamet et al., 2011). Ultimately, greater investigation of multi-modal machine learning could unravel the value of such integration across domains, and offer approaches to aiding continual learning in settings where the environment is unpredictable or multimodal.
The role of attention in human continual learning was underlined by a recent study endowing ANNs with a ‘hard attention mask’, an attentional gating mechanism directly inspired by human cognitive function (Serrà et al., 2018). This substantially decreased catastrophic forgetting in this model when trained on image classification tasks, thereby emphasising attention as an important contribution to continual learning.
Conclusion:
Advances in deep learning have accelerated in recent years, capturing the imagination of researchers and the public alike with their capacity to achieve superhuman performance on tasks, and offer novel scientific insights. However, if machine learning pipelines are ever going to dynamically learn new tasks in real time, with interfering goals and multiple input datasets, the continual learning problem must be addressed. In this review, several of the most promising avenues of research have been appraised, with many of these deriving inspiration from neuroscience. Although much progress has been made, no existing approach adequately solves the continual learning problem. This review argues that bridging continual learning research with neuroscience might offer novel insights and inspiration, ultimately guiding the development of novel approaches to catastrophic forgetting which bring the performance of artificial agents closer to that of humans – assimilating knowledge and skills over time and experience.
References:
Links to selected references of interest are additionally included in the main text
Aimone, J.B., Li, Y., Lee, S.W., Clemenson, G.D., Deng, W. and Gage, F.H., 2014. Regulation and function of adult neurogenesis: from genes to cognition. Physiological reviews, 94(4), pp.991-1026. (https://pubmed.ncbi.nlm.nih.gov/25287858/)
Barnett S.M., Ceci, S.J. When and where do we apply what we learn?: A taxonomy for far transfer. Psychol. Bull. 128, 612-637 (2002). (https://pubmed.ncbi.nlm.nih.gov/12081085/)
Bengio, Y. 2012. Practical recommendations for gradient-based training of deep architectures. In Tricks of the Trade, Second Edition, volume 7700 of Theoretical Computer Science and General Issues. Springer-Verlag. 437–478. (https://arxiv.org/abs/1206.5533)
Bengio, Y., Louradour, J., Collobert, R. & Weston, J. (2009), Curriculum learning, pp. 41–48 (https://ronan.collobert.com/pub/matos/2009_curriculum_icml.pdf)
Cortes, C., Gonzalvo, X., Kuznetsov, V., Mohri, M. and Yang, S., 2017, July. Adanet: Adaptive structural learning of artificial neural networks. In International conference on machine learning (pp. 874-883). PMLR. (https://arxiv.org/abs/1607.01097)
C. Wu, L. Herranz, X. Liu, J. van de Weijer, and B. Raducanu, ‘‘Memory replay GANs: Learning to generate new categories without forgetting,’’ in Proc. Adv. Neural Inf. Process. Syst. (NIPS), Montreal, QC, Canada, 2018, pp. 5964–5974. (https://arxiv.org/abs/1809.02058)
Constantinescu, A.O., J.X. O’Reilly, T.E. Behrens. Organizing conceptual knowledge in humans with a gridlike code. Science, 352 (2016), pp. 1464-1468. (https://science.sciencemag.org/content/352/6292/1464)
D. Bendor, H.J. Spiers. Does the hippocampus map out the future? Trends Cogn. Sci., 20 (2016), pp. 167-169. (https://www.sciencedirect.com/science/article/abs/pii/S1364661316000218)
Dave AS, Margoliash D. Song replay during sleep and computational rules for sensorimotor vocal learning. Science 290: 812–816, 2000. (https://science.sciencemag.org/content/290/5492/812)
David Silver, Thomas Hubert, Julian Schrittwieser, Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, Timothy Lillicrap, Karen Simonyan, and Demis Hassabis. A general reinforcement learning algorithm that masters chess, shogi, and go through self-play. Science, 362(6419):1140–1144, 2018. (https://science.sciencemag.org/content/362/6419/1140)
Doumas, L., Hummel, J. & Sandhofer, C. (2008), ‘A theory of the discovery and predication of relational concepts’, Psychological Review 115, 1–43. (https://pubmed.ncbi.nlm.nih.gov/18211183/)
Draelos, T.J., Miner, N.E., Lamb, C.C., Cox, J.A., Vineyard, C.M., Carlson, K.D., Severa, W.M., James, C.D. and Aimone, J.B., 2017, May. Neurogenesis deep learning: Extending deep networks to accommodate new classes. In 2017 International Joint Conference on Neural Networks (IJCNN) (pp. 526-533). IEEE. (https://ieeexplore.ieee.org/document/7965898)
Dragoi G., Tonegawa S. Preplay of future place cell sequences by hippocampal cellular assemblies. Nature. 2011; 469: 397-40. (https://pubmed.ncbi.nlm.nih.gov/21179088/)
Elman, J. L. (1993), ‘Learning and development in neural networks: The importance of starting small’, Cognition 48 (1), 71–99. (https://www.sciencedirect.com/science/article/abs/pii/0010027793900584)
F. Khan, X. Zhu, and B. Mutlu. How do humans teach: On curriculum learning and teaching dimension. NIPS, 2011. (https://proceedings.neurips.cc/paper/2011/hash/f9028faec74be6ec9b852b0a542e2f39-Abstract.html)
Flesch, T. et al. Comparing continual task learning in minds and machines. PNAS 115 (44): E10313- E10322 (2018). (https://www.pnas.org/content/115/44/E10313)
French, R. M. (1999), ‘Catastrophic forgetting in connectionist networks’, Trends in Cognitive Sciences 3 (4), 128–135. (https://www.sciencedirect.com/science/article/abs/pii/S1364661399012942)
Fusi, S., Drew, P.J. and Abbott, L.F., 2005. Cascade models of synaptically stored memories. Neuron, 45(4), pp.599-611. (https://www.sciencedirect.com/science/article/pii/S0896627305001170)
G. I. Parisi, R. Kemker, J. L. Part, C. Kanan, and S. Wermter. Continual lifelong learning with neural networks: A review. arXiv preprint arXiv:1802.07569, 2018. (https://www.sciencedirect.com/science/article/pii/S0893608019300231)
G. Kasparov. Chess, a drosophila of reasoning. Science (New York, NY), 362(6419):1087, 2018. (https://science.sciencemag.org/content/362/6419/1087)
Gepperth, A. & Karaoguz, C. (2015), ‘A bio-inspired incremental learning architecture for applied perceptual problems’, Cognitive Computation 8 (5), 924–934. (https://hal.archives-ouvertes.fr/hal-01418123/document)
Girardeau G., Benchenane K., Wiener S.I., Buzsaki G., Zugaro M.B. Selective suppression of hippocampal ripples impairs spatial memory. Nat. Neurosci. 2009; 12: 1222-1223 (https://www.nature.com/articles/nn.2384)
Goode, S., Magill, R.A. Contextual interference effects in three badminton serves. Res. Q. Exerc. Sport (1986). (https://www.tandfonline.com/doi/abs/10.1080/02701367.1986.10608091)
Goodfellow, I.J., J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A.C. Courville, and Y. Bengio. Generative adversarial nets. In Proceedings of NIPS, pages 2672–2680, 2014. (https://arxiv.org/abs/1406.2661)
Graves, A., Wayne, G., Reynolds, M., Harley, T., Danihelka, I., Grabska-Barwinska, A., Colmenarejo, S. G., Grefenstette, E., Ramalho, T. & Agapiou, J. e. a. (2016), ‘Hybrid computing using a neural network with dynamic external memory’, Nature 538, 471–476. (https://www.nature.com/articles/nature20101)
Graves, A., Bellemare, M. G., Menick, J., Munos, R. & Kavukcuoglu, K. (2017), Automated curriculum learning for neural networks, arXiv:1704.03003. (https://arxiv.org/abs/1704.03003)
H.F. Olafsdottir, D. Bush, C. Barry. The role of hippocampal replay in memory and planning. Curr. Biol., 28 (2018), pp. R37-R50. (https://www.sciencedirect.com/science/article/pii/S0960982217314410)
Hadsell, R., Rao, D., Rusu, A.A. and Pascanu, R., 2020. Embracing Change: Continual Learning in Deep Neural Networks. Trends in Cognitive Sciences. (https://www.cell.com/trends/cognitive-sciences/fulltext/S1364-6613(20)30219-9)
Hassabis, D., Kumaran, D., Summerfield, C. & Botvinick, M. (2017), ‘Neuroscience-inspired artificial intelligence’, Neuron Review 95 (2), 245–258. (https://www.cell.com/neuron/pdf/S0896-6273(17)30509-3.pdf)
Hayes, T.L., Kafle, K., Shrestha, R., Acharya, M. and Kanan, C., 2020, August. Remind your neural network to prevent catastrophic forgetting. In European Conference on Computer Vision (pp. 466-483). Springer, Cham. (https://arxiv.org/abs/1910.02509)
Higgins, I., Matthey, L., Glorot, X., Pal, A., Uria, B., Blundell, C., Mohamed, S., and Lerchner, A. (2016). Early visual concept learning with unsupervised deep learning. arXiv, arXiv:160605579. (https://arxiv.org/abs/1606.05579)
Hinton, G. E. & Plaut, D. C. (1987), Using fast weights to deblur old memories, Proceedings of the Annual Conference of the Cognitive Science Society, pp. 177–186. (https://www.cs.toronto.edu/~hinton/absps/fastweights87.pdf)
Hinton, G.E. (1986). Learning Distributed Representations of Concepts. In Proceedings of the Eighth Annual Conference of the Cognitive Science Society (Amherst 1986), Hillsdale: Erlbaum. (http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.408.7684&rep=rep1&type=pdf)
Hinton, G., Vinyals, O. and Dean, J., 2015. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531. (https://arxiv.org/abs/1503.02531)
Holyoak, K. J. , & Thagard, P. (1997). The analogical mind. American Psychologist, 52, 35–44. (https://mitpress.mit.edu/books/analogical-mind)
Huszár, F., 2018. Note on the quadratic penalties in elastic weight consolidation. Proceedings of the National Academy of Sciences, p.201717042. (https://www.pnas.org/content/115/11/E2496)
IDC Whitepaper, 2017. https://www.import.io/wp-content/uploads/2017/04/Seagate-WP-DataAge2025-March-2017.pdf
Jegou, H., Douze, M. and Schmid, C., 2010. Product quantization for nearest neighbor search. IEEE transactions on pattern analysis and machine intelligence, 33(1), pp.117-128. (https://lear.inrialpes.fr/pubs/2011/JDS11/jegou_searching_with_quantization.pdf)
Kemker, R., McClure, M., Abitino, A., Hayes, T. and Kanan, C., 2018, April. Measuring catastrophic forgetting in neural networks. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 32, No. 1). (https://arxiv.org/abs/1708.02072)
Kirkpatrick, J., Pascanu, R., Rabinowitz, N., Veness, J., Desjardins, G., Rusu, A.A., Milan, K., Quan, J., Ramalho, T., Grabska-Barwinska, A. and Hassabis, D., 2017. Overcoming catastrophic forgetting in neural networks. Proceedings of the national academy of sciences, 114(13), pp.3521-3526. (https://arxiv.org/abs/1612.00796)
Krueger, K. A. & Dayan, P. (2009), ‘Flexible shaping: how learning in small steps helps’, Cognition 110, 380–394. (https://www.sciencedirect.com/science/article/abs/pii/S0010027708002850)
Kumaran, D., Hassabis, D. & McClelland, J. L. (2016), ‘What learning systems do intelligent agents need? complementary learning systems theory updated’, Trends in Cognitive Sciences 20 (7), 512– 534. (https://www.cell.com/trends/cognitive-sciences/fulltext/S1364-6613(16)30043-2)
LeCun, Y., Bengio, Y. & Hinton, G. (2015), ‘Deep learning’, Nature 521, 436–444. (https://www.nature.com/articles/nature14539)
LeCun, Y., Cortes, C.: The MNIST database of handwritten digits (1998). (http://yann.lecun.com/exdb/mnist/)
Legg, S., Hutter, M. A collection of definitions of intelligence. arXiv:10.1207/s15327051hci0301_2. Preprint, posted June 25th, 2007. (https://arxiv.org/abs/0706.3639)
Li, Z. and Hoiem, D., 2017. Learning without forgetting. IEEE transactions on pattern analysis and machine intelligence, 40(12), pp.2935-2947. (https://arxiv.org/abs/1606.09282)
Liu, Y., Dolan, R.J., Kurth-Nelson, Z. and Behrens, T.E., 2019. Human replay spontaneously reorganizes experience. Cell, 178(3), pp.640-652. (https://www.sciencedirect.com/science/article/pii/S0092867419306403)
Losonczy, A., Makara, J.K. and Magee, J.C., 2008. Compartmentalized dendritic plasticity and input feature storage in neurons. Nature, 452(7186), pp.436-441. (https://www.nature.com/articles/nature06725)
M. Schönauer, S. Alizadeh, H. Jamalabadi, A. Abraham, A. Pawlizki, S. Gais. Decoding material-specific memory reprocessing during sleep in humans. Nat. Comm., 8 (2017). (https://www.nature.com/articles/ncomms15404)
Marblestone A.H., Wayne G., Kording K.P. Toward an integration of deep learning and neuroscience. Front. Comput. Neurosci. 2016; 10: 94 (https://www.frontiersin.org/articles/10.3389/fncom.2016.00094/full)
Mareschal, D., Johnson, M., Sirios, S., Spratling, M., Thomas, M. & Westermann, G. (2007), Neuroconstructivism: How the brain constructs cognition, Oxford: Oxford University Press.
Masse, N.Y. et al. Alleviating catastrophic forgetting using context-dependent gating and synaptic stabilization. arXiv preprint arXiv:1802.01569 (2018). (https://www.pnas.org/content/115/44/E10467)
McClelland, J. L., McNaughton, B. L. & O’Reilly, R. C. (1995), ‘Why there are complementary learning systems in the hippocampus and neocortex: Insights from the successes and failures of connectionist models of learning and memory’, Psychological Review 102, 419–457. (https://pubmed.ncbi.nlm.nih.gov/7624455/)
McCloskey, M. & Cohen, N. J. (1989), ‘Catastrophic interference in connectionist networks: The sequential learning problem’, The Psychology of Learning and Motivation 24, 104–169. (https://www.sciencedirect.com/science/article/pii/S0079742108605368)
Mnih, V. et al. Asynchronous methods for deep reinforcement learning. arXiv: 1602.01783v2. (https://arxiv.org/abs/1602.01783)
Mnih, V. et al. Human-level control through deep reinforcement learning. Nature 518: 529-533 (2015). (https://www.nature.com/articles/nature14236)
Ngiam, J. et al. Multimodal deep learning. In International Conference on Machine Learning (ICML), Bellevue, USA, June 2011. (https://dl.acm.org/doi/10.5555/3104482.3104569)
O’Reilly, R. C. (2004), The Division of Labor Between the Neocortex and Hippocampus. Connectionist Modeling in Cognitive (Neuro-)Science, George Houghton, Ed., Psychology Press. (https://www.taylorfrancis.com/chapters/division-labor-neocortex-hippocampus-randall-reilly/e/10.4324/9780203647110-24)
Palatucci, M.M., Pomerleau, D.A., Hinton, G.E. and Mitchell, T., 2009. Zero-shot learning with semantic output codes. (https://www.cs.toronto.edu/~hinton/absps/palatucci.pdf)
Pallier, C., Dehaene, S., Poline, J.-B., LeBihan, D., Argenti, A.-M., Dupoux, E. & Mehler, J. (2003), ‘Brain imaging of language plasticity in adopted adults: can a second language replace a first?’, Cerebral Cortex 13, 155–161. (https://academic.oup.com/cercor/article/13/2/155/270786)
Pan, S. J. & Yang, Q. (2010), ‘A survey on transfer learning’, IEEE Transactions on Knowledge and Data Engineering 22 (10), 1345–1359. (https://journalofbigdata.springeropen.com/articles/10.1186/s40537-016-0043-6)
Parisi, G. I., Tani, J., Weber, C. & Wermter, S. (2017), ‘Lifelong learning of humans actions with deep neural network self-organization’, Neural Networks 96, 137–149. (https://www.sciencedirect.com/science/article/pii/S0893608017302034)
Parisi, G., Tani, J., Weber, C. & Wermter, S. (2018), Lifelong learning of spatiotemporal representations with dual-memory recurrent self-organization, arXiv:1805.10966. (https://arxiv.org/abs/1805.10966)
PyTorch implementation of Deep Generative Replay. https://github.com/kuc2477/pytorch-deep-generative-replay
Radford, L. Metz, and S. Chintala. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv preprint arXiv:1511.06434, 2015. (https://arxiv.org/abs/1511.06434)
Rasch, B. Memory Formation: Let’s Replay. Elife e43832 (2018). (https://elifesciences.org/articles/43832)
Rebuffi, S.-A., Kolesnikov, A., Sperl, G. & Lampert, C. H. (2016), iCaRL: Incremental classifier and representation learning, arXiv:1611.07725. (https://arxiv.org/abs/1611.07725)
Ring, M.B., 1998. CHILD: A first step towards continual learning. In Learning to learn (pp. 261-292). Springer, Boston, MA. (https://link.springer.com/article/10.1023/A:1007331723572)
Robins, A. V. (1995), ‘Catastrophic forgetting, rehearsal and pseudorehearsal’, Connection Science 7 (2), 123–146. (https://www.tandfonline.com/doi/abs/10.1080/09540099550039318)
Rudou, JD et al. Strengthening individual memories by reactivating them during sleep. Science 326L 1079, 2009. (https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2990343/)
Rusu, A. A., Rabinowitz, N. C., Desjardins, G., Soyer, H., Kirkpatrick, J., Kavukcuoglu, K., Pascanu, R. & Hadsell, R. (2016), Progressive neural networks, arXiv:1606.04671. (https://arxiv.org/abs/1606.04671)
S. Goldman and M. Kearns. On the complexity of teaching. Journal of Computer and Systems Sciences, 50(1):20–31, 1995. (https://dl.acm.org/doi/10.1006/jcss.1995.1003)
Serrà, J. et al. Overcoming Catastrophic Forgetting with Hard Attention to the task. arXiv preprint arXiv:1801.01423 (2018). (https://arxiv.org/abs/1801.01423)
Shin, H., Lee, J. K., Kim, J. & Kim, J. (2017), Continual learning with deep generative replay, NIPS’17, Long Beach, CA. (https://arxiv.org/abs/1705.08690)
Spence, C. (2010), ‘Crossmodal spatial attention’, Annals of the New York Academy of Sciences 1191, 182–200. (https://pubmed.ncbi.nlm.nih.gov/20392281/)
Spence, C. (2014), ‘Orienting attention: A crossmodal perspective’, The Oxford Handbook of Attention. Oxford, UK: Oxford University Press pp. 446–471.
Stein, B. E. & Meredith, M. A. (1993), The merging of the senses , The MIT Press, Cambridge, MA, US.
Stein, B. E., Stanford, T. R. & Rowland, B. A. (2014), ‘Development of multisensory integration from the perspective of the individual neuron’, Nature Reviews Neuroscience 15 (8), 520–535. (https://www.nature.com/articles/nrn3742)
Tenenbaum, J.B., Kemp, C., Griffiths, T.L. and Goodman, N.D., 2011. How to grow a mind: Statistics, structure, and abstraction. science, 331(6022), pp.1279-1285. (https://science.sciencemag.org/content/331/6022/1279)
Teyler, T.J. and Rudy, J.W., 2007. The hippocampal indexing theory and episodic memory: updating the index. Hippocampus, 17(12), pp.1158-1169. (https://pubmed.ncbi.nlm.nih.gov/17696170/)
Thrun, S. & Mitchell, T. (1995), ‘Lifelong robot learning’, Robotics and Autonomous Systems 15, 25–46. (https://www.sciencedirect.com/science/article/abs/pii/092188909500004Y)
van de Ven, G.M., Siegelmann, H.T. and Tolias, A.S., 2020. Brain-inspired replay for continual learning with artificial neural networks. Nature communications, 11(1), pp.1-14. (https://www.nature.com/articles/s41467-020-17866-2)
Vinyals, O., Blundell, C., Lillicrap, T., Kavukcuoglu, K. and Wierstra, D., 2016. Matching networks for one shot learning. arXiv preprint arXiv:1606.04080. (https://arxiv.org/abs/1606.04080)
W.E. Skaggs, B.L. McNaughton, M.A. Wilson, C.A. Barnes. Theta phase precession in hippocampal neuronal populations and the compression of temporal sequences. Hippocampus, 6 (1996), pp. 149- 173. (https://pubmed.ncbi.nlm.nih.gov/8797016/)
Weiss, K., Khoshgoftaar, T. M. & Wang, D.-D. (2016), ‘A survey of transfer learning’, Journal of Big Data 3 (9). (https://journalofbigdata.springeropen.com/articles/10.1186/s40537-016-0043-6)
Yang, G., Pan, F. and Gan, W.B., 2009. Stably maintained dendritic spines are associated with lifelong memories. Nature, 462(7275), pp.920-924. (https://www.nature.com/articles/nature08577)
Yosinski, J. et al. How transferable are features in deep neural networks? In Advances in Neural Information Processing Systems, pages 3320–3328, 2014. (https://arxiv.org/abs/1411.1792)
Zenke, F., Poole, B. and Ganguli, S., 2017, July. Continual learning through synaptic intelligence. In International Conference on Machine Learning (pp. 3987-3995). PMLR. (https://arxiv.org/abs/1703.04200)