Marching into the LLM Era: Why and How AI/ML Research Labs Should Embrace Cloud Computation
Cover image from the paper "Hidden Technical Debt in Machine Learning Systems".
Why Should We Embrace Cloud Computation
The advent of GPT-4 and similar models has fueled a paradigm shift in the field of artificial intelligence, transforming the way we approach natural language processing and machine learning. With models growing in size and complexity, the computational demands associated with training, fine-tuning, and deployment have soared to unprecedented levels.
In the past, academic researchers often relied on building their own machines or even developing algorithms using their laptops, as their research typically did not necessitate extensive computational resources. This "asset-light" research era allowed researchers to focus on innovation without being burdened by the need for costly, high-end infrastructure.
However, the emergence of the LLM era has presented significant challenges to academic researchers with regard to the infrastructure required for training, fine-tuning, and deploying models. LLMs frequently necessitate the use of high-end data-center GPUs, such as the NVIDIA A100, as well as ultra-high cross-machine network bandwidth with RDMA support (typically facilitated by tailored Ethernet cards with RoCE support or InfiniBand cards). Setting up this complex infrastructure can be both difficult and expensive, marking a shift toward an "asset-heavy" research era for AI/ML researchers.
Thankfully, the rise of cloud computing has provided academic labs with the opportunity to participate in the LLM era in a more "asset-light" manner. By purchasing computational resources from cloud computing platforms, researchers can access state-of-the-art infrastructure without bearing the full cost of ownership. These platforms often offer flexible payment options, such as monthly billing or even "pay-as-you-go" (charging based on usage), enabling researchers to kickstart their LLM projects with just a few hundred dollars. A prime example of this shift is Databricks' recent introduction of a Dolly model using standard machines in Amazon Web Services (AWS), as detailed in their blog.
In the future, it is indisputable that academic labs focusing on AI/ML will need to embrace cloud computing platforms, whether through private or public cloud solutions. The days of purchasing machines and GPUs, finding space to house them, and dealing with endless maintenance and countless breakdowns will become a thing of the past for most academic labs. Consequently, future researchers will no longer be burdened by these concerns.
How Should We Embrace Cloud Computation
Cloud computing has revolutionized the way we access and process information by providing computing resources, such as processing power, storage, and memory, as a service over the internet. Major players like Google Cloud, AWS, and Alibaba Cloud, as well as owners of supercomputers, are capitalizing on this technology to deliver cost-effective, on-demand resources to individuals and businesses alike. For computer science beginners, understanding cloud computing can be overwhelming. Therefore, we will break down the core components and discuss how they work together to provide efficient cloud computation services.
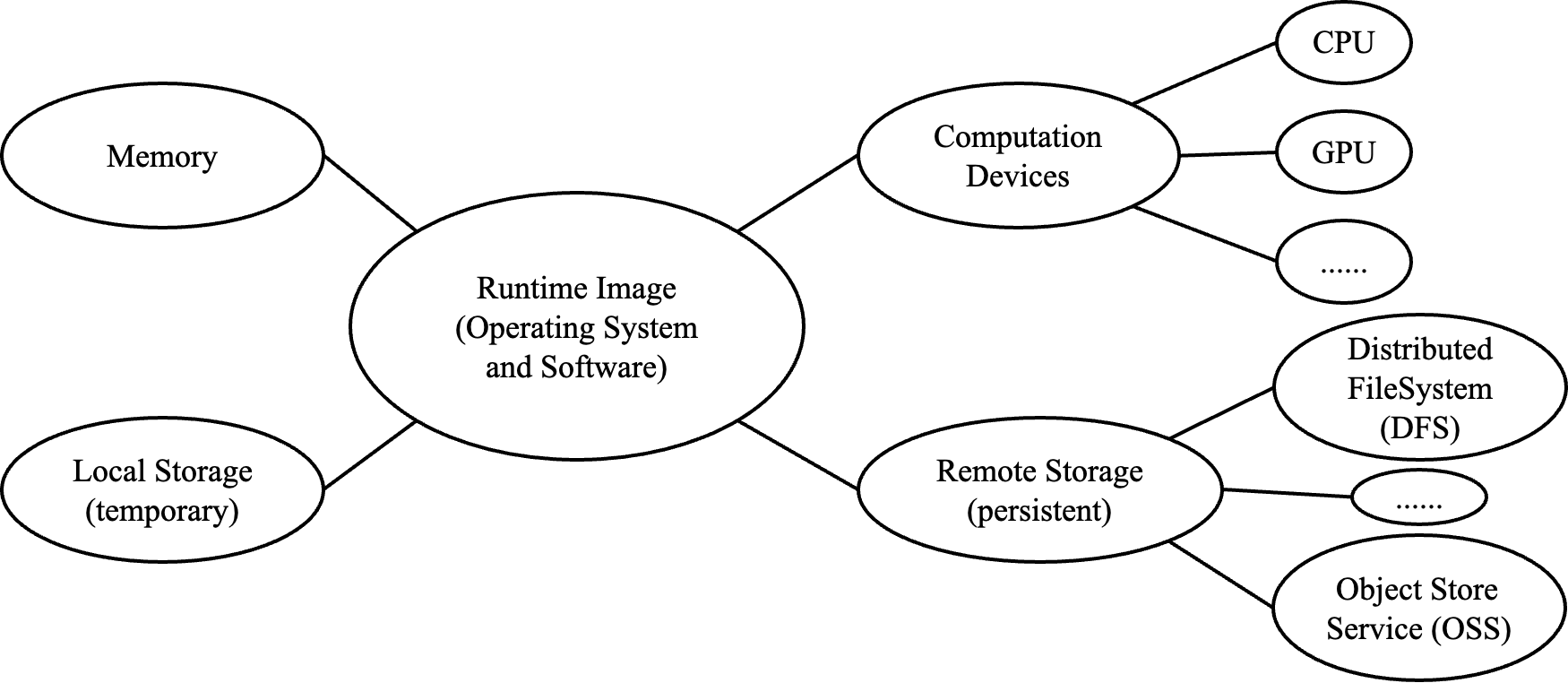
People might be too familiar with their local machines to notice functionality sectors of computation and storage. There are five key parts to understand when learning about or migrating to a new cloud computing vendor, as depicted in the figure:
-
Computation devices: These are the hardware components responsible for processing data and executing instructions. Cloud computing vendors offer various types of computation devices such as CPUs (central processing units), GPUs (graphics processing units), and FPGAs (field-programmable gate arrays). Each vendor has its naming conventions for these devices, usually linked to their pricing and instance types. For example, the "p4d.24xlarge" instance on AWS has 8 A100 GPUs (40GB). This information can typically be found on the vendor's instance type or pricing page.
-
Memory: This is the temporary storage used for holding data and instructions while the computation devices process them. The amount of memory provided by a cloud computing vendor varies depending on the pricing plan. Memory is less expensive than computation devices, but it's still essential for efficient processing and execution of tasks.
-
Local Storage: This refers to the disk space allocated to each machine in the cloud. It's another factor that affects the pricing plan but is usually less significant than memory since disk space is cheaper. However, it's crucial to note that local storage is temporary; data will be lost when the machine restarts.
-
Remote Storage: Since local storage is temporary, cloud computing vendors must offer a persistent storage solution. This typically comes in the form of a mounted directory (e.g., /data) that is connected to a remote storage filesystem for direct read/write access or periodically synchronized with remote storage. The backend storage can be a distributed filesystem like HDFS or an object store service. Remember that cloud computing vendors may charge users for the storage they consume.
-
Runtime Image: This term "image" is not the kind of photos we see in the Internet, but the analogy applies: an image is a snapshot of a moment or scene in time; and a runtime image is a snapshot of an operating system (including the state of the filesystem, the software installed, and the configuration settings at a specific point in time). That said, a runtime image contains an operating system and peripheral softwares, which are responsible for interacting with computation devices/memory/storage backends.
Out of the five components mentioned above, computation devices, memory, local storage, and remote storage are relatively straightforward for users to grasp, as they primarily involve paying for the required resources. The runtime image, on the other hand, is the most complex aspect. Some cloud computing vendors support customized images, while others provide base images with bare operating systems.
If a vendor allows customized images, it's highly recommended to create one to save money. Cloud computing charges typically begin when the machine is ready for users to log in, and the time spent installing common software will also incur charges. By using a customized image with pre-installed software, users can start working as soon as the machine is available, reducing costs and increasing efficiency.
In summary, understanding the five core components of cloud computing – computation devices, memory, local storage, remote storage, and runtime image – is essential for computer science beginners looking to explore or migrate to a new cloud computing vendor. By grasping these concepts, users can make informed decisions about which vendor best meets their needs and how to optimize their cloud computing experience.
A daily image for AI/ML researchers
I have recently migrated to cloud computation, and spent several days figuring out how to build a customized image (especially in an environment with limited Internet access). The process of building the image is recorded at a GituHub repo. The image contains the following support:
- GPU support (cuda 11.7 toolkit with dev tools)
- jupyter lab/notebook interactive programming based on web UI
- tensorboard visualization
- full-stack ssh capacity
- latest pytorch environment (1.13) with miniconda support
- OpenMMLab MMCV(1.7)/MMDetection/MMClassification support
- MLNX OFED support (version 5.4 for distributed training with RDMA)
- Deepspeed with Huggingface Transformers/Datasets/Accelerate
This image can cover basic development of large language models: single-machine-single-GPU (for inference), single-machine-multiple-GPUs (for fine-tuning), and multiple-machine-multiple-GPUs (for pre-training large language models). In short, it supports most development cases with data-parallel training and inference, but not suitable for model-parallel training with super large language models. I think most AI/ML researchers will not bother to train super large language models, so that part is not included by design.
If one does not want to build a new image, he can directly use the image I build: just fill in
docker.io/youkaichao/pytorch113_cu117_ubuntu2004:openmmlab-ofed-deepspeed in the image field when creating a machine from cloud computation vendors, or use docker pull youkaichao/pytorch113_cu117_ubuntu2004:openmmlab-ofed-deepspeed command.If one does want to build a new image, he can follow the guide at the repository. It is rather simple and self-explained.
Conclusion
As we look to the future of computing, it's becoming increasingly clear that it may soon resemble the way we access electricity: through a country-level infrastructure. It would be quite peculiar if every household were to construct their own electric generator to power their daily needs. Similarly, it is odd to imagine that every research lab would build and maintain its own computing machine to conduct their daily research. Cloud computation represents a significant leap towards transforming computation into a public good, much like electricity. We should wholeheartedly embrace this trend and adapt to it as courageously as possible.
Cloud computing allows us to harness the power of vast, interconnected networks of computers, offering virtually limitless resources for storage and processing. This innovative technology not only democratizes access to computational resources but also fosters collaboration and efficiency on a global scale. By pooling resources and sharing infrastructure, researchers and businesses alike can benefit from cutting-edge hardware and software without having to invest in costly, dedicated systems.
As we continue to witness rapid advancements in technology, it is crucial to understand the transformative potential of cloud computing. Embracing this paradigm shift will enable us to move towards a future where computation is a ubiquitous resource, readily available to everyone, just like electricity. This transformation will ultimately lead to more efficient use of resources, increased collaboration, and the acceleration of innovation across all fields of study and industry.
Recommended for you
Using Mathpix and NaviLens to create accessible math flashcards
Using Mathpix and NaviLens to create accessible math flashcards
Students with print disabilities, due to blindness, low vision, learning disabilities or physical disabilities, can greatly benefit from accessible math flashcards and tutorials. Mathpix greatly reduces the amount of work required to create these by capturing text and math from a variety of sources making them ready for conversion to print or braille.