Let's start by talking about a few examples of supervised learning problems. Suppose we have a dataset giving the living areas and prices of 4747 houses from Portland, Oregon:
Living area ("feet"^(2))\left({\text{feet}}^{2}\right)
Price (1000$"s")\left(1000\$\text{s}\right)
2104
400
1600
330
2400
369
1416
232
3000
540
vdots\vdots
vdots\vdots
We can plot this data:
Given data like this, how can we learn to predict the prices of other houses in Portland, as a function of the size of their living areas?
To establish notation for future use, we'll use x^((i))x^{(i)} to denote the "input" variables (living area in this example), also called input features, and y^((i))y^{(i)} to denote the "output" or target variable that we are trying to predict (price). A pair (x^((i)),y^((i)))\left(x^{(i)}, y^{(i)}\right) is called a training example, and the dataset that we'll be using to learn–a list of nn training examples {(x^((i)),y^((i)));i=1,dots,n}\left\{\left(x^{(i)}, y^{(i)}\right) ; i=1, \ldots, n\right\}–is called a training set. Note that the superscript "i(i)i(i)" in the notation is simply an index into the training set, and has nothing to do with exponentiation. We will also use X\mathcal{X} denote the space of input values, and Y\mathcal{Y} the space of output values. In this example, X=Y=R\mathcal{X}=\mathcal{Y}=\mathbb{R}.
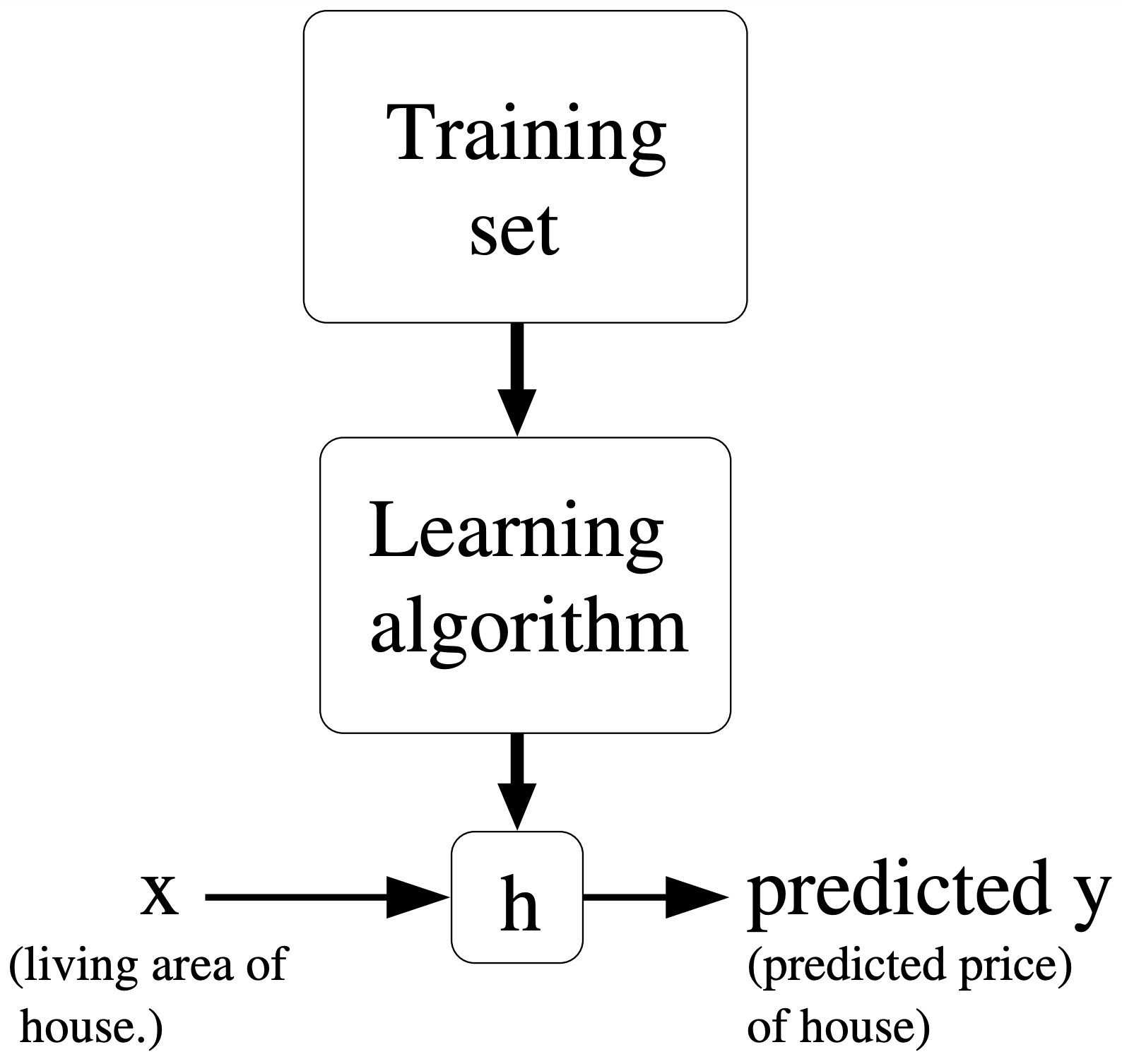
To describe the supervised learning problem slightly more formally, our goal is, given a training set, to learn a function h:X|->Yh: \mathcal{X} \mapsto \mathcal{Y} so that h(x)h(x) is a "good" predictor for the corresponding value of yy. For historical reasons, this function hh is called a hypothesis. Seen pictorially, the process is therefore like this:
When the target variable that we're trying to predict is continuous, such as in our housing example, we call the learning problem a regression problem. When yy can take on only a small number of discrete values (such as if, given the living area, we wanted to predict if a dwelling is a house or an apartment, say), we call it a classification problem.
Part I
Linear Regression
To make our housing example more interesting, let's consider a slightly richer dataset in which we also know the number of bedrooms in each house:
Living area ("feet"^(2))\left(\text{feet}^{2}\right)
#bedrooms
Price (1000$"s")\left(1000\$\text{s}\right)
2104
3
400
1600
3
330
2400
3
369
1416
2
232
3000
4
540
vdots\vdots
vdots\vdots
vdots\vdots
Here, the xx's are two-dimensional vectors in R^(2)\mathbb{R}^{2}. For instance, x_(1)^((i))x_{1}^{(i)} is the living area of the ii-th house in the training set, and x_(2)^((i))x_{2}^{(i)} is its number of bedrooms. (In general, when designing a learning problem, it will be up to you to decide what features to choose, so if you are out in Portland gathering housing data, you might also decide to include other features such as whether each house has a fireplace, the number of bathrooms, and so on. We'll say more about feature selection later, but for now let's take the features as given.)
To perform supervised learning, we must decide how we're going to represent functions/hypotheses hh in a computer. As an initial choice, let's say we decide to approximate yy as a linear function of xx:
Here, the theta_(i)\theta_{i}'s are the parameters (also called weights) parameterizing the space of linear functions mapping from X\mathcal{X} to Y\mathcal{Y}. When there is no risk of confusion, we will drop the theta\theta subscript in h_(theta)(x)h_{\theta}(x), and write it more simply as h(x)h(x). To simplify our notation, we also introduce the convention of letting x_(0)=1x_{0}=1 (this is the intercept term), so that
h(x)=sum_(i=0)^(d)theta_(i)x_(i)=theta^(T)x,h(x)=\sum_{i=0}^{d} \theta_{i} x_{i}=\theta^{T} x ,
where on the right-hand side above we are viewing theta\theta and xx both as vectors, and here dd is the number of input variables (not counting x_(0)x_{0}).
Now, given a training set, how do we pick, or learn, the parameters theta\theta? One reasonable method seems to be to make h(x)h(x) close to yy, at least for the training examples we have. To formalize this, we will define a function that measures, for each value of the theta\theta's, how close the h(x^((i)))h(x^{(i)})'s are to the corresponding y^((i))y^{(i)}'s. We define the cost function:
If you've seen linear regression before, you may recognize this as the familiar least-squares cost function that gives rise to the ordinary least squares regression model. Whether or not you have seen it previously, let's keep going, and we'll eventually show this to be a special case of a much broader family of algorithms.
1. LMS algorithm
We want to choose theta\theta so as to minimize J(theta)J(\theta). To do so, let's use a search algorithm that starts with some "initial guess" for theta\theta, and that repeatedly changes theta\theta to make J(theta)J(\theta) smaller, until hopefully we converge to a value of theta\theta that minimizes J(theta)J(\theta). Specifically, let's consider the gradient descent algorithm, which starts with some initial theta\theta, and repeatedly performs the update:
(This update is simultaneously performed for all values of j=0,dots,dj=0, \ldots, d.) Here, alpha\alpha is called the learning rate. This is a very natural algorithm that repeatedly takes a step in the direction of steepest decrease of JJ.
In order to implement this algorithm, we have to work out what is the partial derivative term on the right hand side. Let's first work it out for the case of if we have only one training example (x,y)(x, y), so that we can neglect the sum in the definition of JJ. We have:
The rule is called the LMS update rule (LMS stands for "least mean squares"), and is also known as the Widrow-Hoff learning rule. This rule has several properties that seem natural and intuitive. For instance, the magnitude of the update is proportional to the error term (y^((i))-h_(theta)(x^((i))))(y^{(i)}-h_{\theta}(x^{(i)})); thus, for instance, if we are encountering a training example on which our prediction nearly matches the actual value of y^((i))y^{(i)}, then we find that there is little need to change the parameters; in contrast, a larger change to the parameters will be made if our prediction h_(theta)(x^((i)))h_{\theta}(x^{(i)}) has a large error (i.e., if it is very far from y^((i))y^{(i)}).
We'd derived the LMS rule for when there was only a single training example. There are two ways to modify this method for a training set of more than one example. The first is replace it with the following algorithm:
Repeat until convergence {\{
{:(1)theta_(j):=theta_(j)+alphasum_(i=1)^(n)(y^((i))-h_(theta)(x^((i))))x_(j)^((i))","("for every "j):}\begin{equation}
\theta_{j}:=\theta_{j}+\alpha \sum_{i=1}^{n}\left(y^{(i)}-h_{\theta}\left(x^{(i)}\right)\right) x_{j}^{(i)},(\text {for every } j)
\end{equation}
}\}
By grouping the updates of the coordinates into an update of the vector theta\theta, we can rewrite update (1) in a slightly more succinct way:
The reader can easily verify that the quantity in the summation in the update rule above is just del J(theta)//deltheta_(j)\partial J(\theta) / \partial \theta_{j} (for the original definition of JJ). So, this is simply gradient descent on the original cost function JJ. This method looks at every example in the entire training set on every step, and is called batch gradient descent. Note that, while gradient descent can be susceptible to local minima in general, the optimization problem we have posed here for linear regression has only one global, and no other local, optima; thus gradient descent always converges (assuming the learning rate alpha\alpha is not too large) to the global minimum. Indeed, JJ is a convex quadratic function. Here is an example of gradient descent as it is run to minimize a quadratic function.
The ellipses shown above are the contours of a quadratic function. Also shown is the trajectory taken by gradient descent, which was initialized at (48,30)(48,30). The xx's in the figure (joined by straight lines) mark the successive values of theta\theta that gradient descent went through.
When we run batch gradient descent to fit theta\theta on our previous dataset, to learn to predict housing price as a function of living area, we obtain theta_(0)=71.27,theta_(1)=0.1345\theta_{0}=71.27, \theta_{1}=0.1345. If we plot h_(theta)(x)h_{\theta}(x) as a function of xx (area), along with the training data, we obtain the following figure:
If the number of bedrooms were included as one of the input features as well, we get theta_(0)=89.60,theta_(1)=0.1392,theta_(2)=-8.738\theta_{0}=89.60, \theta_{1}=0.1392, \theta_{2}=-8.738.
The above results were obtained with batch gradient descent. There is an alternative to batch gradient descent that also works very well. Consider the following algorithm:
Loop {\{
quad\quad for i=1i = 1 to n,{n, \{
{:(2)theta_(j):=theta_(j)+alpha(y^((i))-h_(theta)(x^((i))))x_(j)^((i))","quad("for every "j):}\begin{equation}
\theta_{j}:=\theta_{j}+\alpha\left(y^{(i)}-h_{\theta}(x^{(i)})\right)x^{(i)}_{j},\quad(\text{for every }j)
\tag{2}
\end{equation}
quad}\quad \}
}\}
By grouping the updates of the coordinates into an update of the vector theta\theta, we can rewrite update (2) in a slightly more succinct way:
In this algorithm, we repeatedly run through the training set, and each time we encounter a training example, we update the parameters according to the gradient of the error with respect to that single training example only. This algorithm is called stochastic gradient descent (also incremental gradient descent). Whereas batch gradient descent has to scan through the entire training set before taking a single step–a costly operation if nn is large–stochastic gradient descent can start making progress right away, and continues to make progress with each example it looks at. Often, stochastic gradient descent gets theta\theta "close" to the minimum much faster than batch gradient descent. (Note however that it may never "converge" to the minimum, and the parameters theta\theta will keep oscillating around the minimum of J(theta)J(\theta); but in practice most of the values near the minimum will be reasonably good approximations to the true minimum.[2]) For these reasons, particularly when the training set is large, stochastic gradient descent is often preferred over batch gradient descent.
2. The normal equations
Gradient descent gives one way of minimizing JJ. Let's discuss a second way of doing so, this time performing the minimization explicitly and without resorting to an iterative algorithm. In this method, we will minimize JJ by explicitly taking its derivatives with respect to the theta_(j)\theta_{j}'s, and setting them to zero. To enable us to do this without having to write reams of algebra and pages full of matrices of derivatives, let's introduce some notation for doing calculus with matrices.
2.1. Matrix derivatives
For a function f:R^(n xx d)|->Rf: \mathbb{R}^{n \times d} \mapsto \mathbb{R} mapping from nn-by-dd matrices to the real numbers, we define the derivative of ff with respect to AA to be:
Thus, the gradient grad_(A)f(A)\nabla_{A} f(A) is itself an nn-by-dd matrix, whose (i,j)(i, j)-element is del f//delA_(ij)\partial f / \partial A_{i j}. For example, suppose A=[[A_(11),A_(12)],[A_(21),A_(22)]]A=\left[\begin{array}{ll}A_{11} & A_{12} \\ A_{21} & A_{22}\end{array}\right] is a 2-by-2 matrix, and the function f:R^(2xx2)|->Rf: \mathbb{R}^{2 \times 2} \mapsto \mathbb{R} is given by
Armed with the tools of matrix derivatives, let us now proceed to find in closed-form the value of theta\theta that minimizes J(theta)J(\theta). We begin by re-writing JJ in matrix-vectorial notation.
Given a training set, define the design matrixXX to be the nn-by-dd matrix (actually nn-by-d+1d+1, if we include the intercept term) that contains the training examples' input values in its rows:
In the third step, we used the fact that a^(T)b=b^(T)aa^{T} b=b^{T} a, and in the fifth step used the facts grad_(x)b^(T)x=b\nabla_{x} b^{T} x=b and grad_(x)x^(T)Ax=2Ax\nabla_{x} x^{T} A x=2 A x for symmetric matrix AA (for more details, see Section 4.3 of "Linear Algebra Review and Reference"). To minimize JJ, we set its derivatives to zero, and obtain the normal equations:
X^(T)X theta=X^(T) vec(y)X^{T} X \theta=X^{T} \vec{y}
Thus, the value of theta\theta that minimizes J(theta)J(\theta) is given in closed form by the equation
When faced with a regression problem, why might linear regression, and specifically why might the least-squares cost function JJ, be a reasonable choice? In this section, we will give a set of probabilistic assumptions, under which least-squares regression is derived as a very natural algorithm.
Let us assume that the target variables and the inputs are related via the equation
where epsilon^((i))\epsilon^{(i)} is an error term that captures either unmodeled effects (such as if there are some features very pertinent to predicting housing price, but that we'd left out of the regression), or random noise. Let us further assume that the epsilon^((i))\epsilon^{(i)} are distributed IID (independently and identically distributed) according to a Gaussian distribution (also called a Normal distribution) with mean zero and some variance sigma^(2)\sigma^{2}. We can write this assumption as "epsilon^((i))∼\epsilon^{(i)} \simN(0,sigma^(2))\mathcal{N}\left(0, \sigma^{2}\right)." I.e., the density of epsilon^((i))\epsilon^{(i)} is given by
The notation "p(y^((i))|x^((i));theta)p\left(y^{(i)} | x^{(i)} ; \theta\right)" indicates that this is the distribution of y^((i))y^{(i)} given x^((i))x^{(i)} and parameterized by theta\theta. Note that we should not condition on theta\theta ("p(y^((i))|x^((i)),theta)p\left(y^{(i)} | x^{(i)}, \theta\right)"), since theta\theta is not a random variable. We can also write the distribution of y^((i))y^{(i)} as y^((i))|x^((i));theta∼N(theta^(T)x^((i)),sigma^(2))y^{(i)} | x^{(i)} ; \theta \sim \mathcal{N}\left(\theta^{T} x^{(i)}, \sigma^{2}\right).
Given XX (the design matrix, which contains all the x^((i))x^{(i)}'s) and theta\theta, what is the distribution of the y^((i))y^{(i)}'s? The probability of the data is given by p( vec(y)|X;theta)p(\vec{y} | X ; \theta). This quantity is typically viewed a function of vec(y)\vec{y} (and perhaps XX), for a fixed value of theta\theta. When we wish to explicitly view this as a function of theta\theta, we will instead call it the likelihood function:
L(theta)=L(theta;X, vec(y))=p( vec(y)∣X;theta).L(\theta)=L(\theta ; X, \vec{y})=p(\vec{y} \mid X ; \theta).
Note that by the independence assumption on the epsilon^((i))\epsilon^{(i)}'s (and hence also the y^((i))y^{(i)}'s given the x^((i))x^{(i)}'s), this can also be written
Now, given this probabilistic model relating the y^((i))y^{(i)}'s and the x^((i))x^{(i)}'s, what is a reasonable way of choosing our best guess of the parameters theta\theta? The principal of maximum likelihood says that we should choose theta\theta so as to make the data as high probability as possible. I.e., we should choose theta\theta to maximize L(theta)L(\theta).
Instead of maximizing L(theta)L(\theta), we can also maximize any strictly increasing function of L(theta)L(\theta). In particular, the derivations will be a bit simpler if we instead maximize the log likelihoodℓ(theta)\ell(\theta):
which we recognize to be J(theta)J(\theta), our original least-squares cost function.
To summarize: Under the previous probabilistic assumptions on the data, least-squares regression corresponds to finding the maximum likelihood estimate of theta\theta. This is thus one set of assumptions under which least-squares regression can be justified as a very natural method that's just doing maximum likelihood estimation. (Note however that the probabilistic assumptions are by no means necessary for least-squares to be a perfectly good and rational procedure, and there may–and indeed there are–other natural assumptions that can also be used to justify it.)
Note also that, in our previous discussion, our final choice of theta\theta did not depend on what was sigma^(2)\sigma^{2}, and indeed we'd have arrived at the same result even if sigma^(2)\sigma^{2} were unknown. We will use this fact again later, when we talk about the exponential family and generalized linear models.
4. Locally weighted linear regression
Consider the problem of predicting yy from x inRx \in \mathbb{R}. The leftmost figure below shows the result of fitting a y=theta_(0)+theta_(1)xy=\theta_{0}+\theta_{1} x to a dataset. We see that the data doesn't really lie on straight line, and so the fit is not very good.
Instead, if we had added an extra feature x^(2)x^{2}, and fit y=theta_(0)+theta_(1)x+theta_(2)x^(2)y=\theta_{0}+\theta_{1} x+\theta_{2} x^{2}, then we obtain a slightly better fit to the data. (See middle figure) Naively, it might seem that the more features we add, the better. However, there is also a danger in adding too many features: The rightmost figure is the result of fitting a 5-th order polynomial y=sum_(j=0)^(5)theta_(j)x^(j)y=\sum_{j=0}^{5} \theta_{j} x^{j}. We see that even though the fitted curve passes through the data perfectly, we would not expect this to be a very good predictor of, say, housing prices (y)(y) for different living areas (x)(x). Without formally defining what these terms mean, we'll say the figure on the left shows an instance of underfitting–in which the data clearly shows structure not captured by the model–and the figure on the right is an example of overfitting. (Later in this class, when we talk about learning theory we'll formalize some of these notions, and also define more carefully just what it means for a hypothesis to be good or bad.)
As discussed previously, and as shown in the example above, the choice of features is important to ensuring good performance of a learning algorithm. (When we talk about model selection, we'll also see algorithms for automatically choosing a good set of features.) In this section, let us briefly talk about the locally weighted linear regression (LWR) algorithm which, assuming there is sufficient training data, makes the choice of features less critical. This treatment will be brief, since you'll get a chance to explore some of the properties of the LWR algorithm yourself in the homework.
In the original linear regression algorithm, to make a prediction at a query point xx (i.e., to evaluate h(x)h(x)), we would:
Fit theta\theta to minimize sum_(i)(y^((i))-theta^(T)x^((i)))^(2)\sum_{i}(y^{(i)}-\theta^{T}x^{(i)})^{2}.
Output theta^(T)x\theta^{T}x.
In contrast, the locally weighted linear regression algorithm does the following:
Fit theta\theta to minimize sum_(i)w^((i))(y^((i))-theta^(T)x^((i)))^(2)\sum_{i}w^{(i)}(y^{(i)}-\theta^{T}x^{(i)})^{2}.
Output theta^(T)x\theta^{T}x.
Here, the w^((i))w^{(i)}'s are non-negative valued weights. Intuitively, if w^((i))w^{(i)} is large for a particular value of ii, then in picking theta\theta, we'll try hard to make (y^((i))-theta^(T)x^((i)))^(2)(y^{(i)}-\theta^{T}x^{(i)})^{2} small. If w^((i))w^{(i)} is small, then the (y^((i))-theta^(T)x^((i)))^(2)(y^{(i)}-\theta^{T}x^{(i)})^{2} error term will be pretty much ignored in the fit.
Note that the weights depend on the particular point xx at which we're trying to evaluate xx. Moreover, if |x^((i))-x||x^{(i)}-x| is small, then w^((i))w^{(i)} is close to 11; and if |x^((i))-x||x^{(i)}-x| is large, then w^((i))w^{(i)} is small. Hence, theta\theta is chosen giving a much higher "weight" to the (errors on) training examples close to the query point xx. (Note also that while the formula for the weights takes a form that is cosmetically similar to the density of a Gaussian distribution, the w^((i))w^{(i)}'s do not directly have anything to do with Gaussians, and in particular the w^((i))w^{(i)} are not random variables, normally distributed or otherwise.) The parameter tau\tau controls how quickly the weight of a training example falls off with distance of its x^((i))x^{(i)} from the query point x;taux ; \tau is called the bandwidth parameter, and is also something that you'll get to experiment with in your homework.
Locally weighted linear regression is the first example we're seeing of a non-parametric algorithm. The (unweighted) linear regression algorithm that we saw earlier is known as a parametric learning algorithm, because it has a fixed, finite number of parameters (the theta_(i)\theta_{i}'s), which are fit to the data. Once we've fit the theta_(i)\theta_{i}'s and stored them away, we no longer need to keep the training data around to make future predictions. In contrast, to make predictions using locally weighted linear regression, we need to keep the entire training set around. The term "non-parametric" (roughly) refers to the fact that the amount of stuff we need to keep in order to represent the hypothesis hh grows linearly with the size of the training set.
Part II
Classification and logistic regression
Let's now talk about the classification problem. This is just like the regression problem, except that the values yy we now want to predict take on only a small number of discrete values. For now, we will focus on the binary classification problem in which yy can take on only two values, 00 and 11. (Most of what we say here will also generalize to the multiple-class case.) For instance, if we are trying to build a spam classifier for email, then x^((i))x^{(i)} may be some features of a piece of email, and yy may be 11 if it is a piece of spam mail, and 00 otherwise. 00 is also called the negative class, and 11 the positive class, and they are sometimes also denoted by the symbols "-" and "+." Given x^((i))x^{(i)}, the corresponding y^((i))y^{(i)} is also called the label for the training example.
5. Logistic regression
We could approach the classification problem ignoring the fact that yy is discrete-valued, and use our old linear regression algorithm to try to predict yy given xx. However, it is easy to construct examples where this method performs very poorly. Intuitively, it also doesn't make sense for h_(theta)(x)h_{\theta}(x) to take values larger than 11 or smaller than 00 when we know that y in{0,1}y \in\{0,1\}.
To fix this, let's change the form for our hypotheses h_(theta)(x)h_{\theta}(x). We will choose
is called the logistic function or the sigmoid function. Here is a plot showing g(z)g(z):
Notice that g(z)g(z) tends towards 11 as z rarr ooz \rightarrow \infty, and g(z)g(z) tends towards 00 as z rarr-ooz \rightarrow-\infty. Moreover, g(z)\mathrm{g}(\mathrm{z}), and hence also h(x)h(x), is always bounded between 00 and 11. As before, we are keeping the convention of letting x_(0)=1x_{0}=1, so that theta^(T)x=theta_(0)+sum_(j=1)^(d)theta_(j)x_(j).\theta^{T} x=\theta_{0}+\sum_{j=1}^{d} \theta_{j} x_{j} .
For now, let's take the choice of gg as given. Other functions that smoothly increase from 00 to 11 can also be used, but for a couple of reasons that we'll see later (when we talk about GLMs, and when we talk about generative learning algorithms), the choice of the logistic function is a fairly natural one. Before moving on, here's a useful property of the derivative of the sigmoid function, which we write as g^(')g^{\prime}:
So, given the logistic regression model, how do we fit theta\theta for it? Following how we saw least squares regression could be derived as the maximum likelihood estimator under a set of assumptions, let's endow our classification model with a set of probabilistic assumptions, and then fit the parameters via maximum likelihood.
Let us assume that
{:[P(y=1∣x;theta)=h_(theta)(x)],[P(y=0∣x;theta)=1-h_(theta)(x)]:}\begin{aligned}
&P(y=1 \mid x ; \theta)=h_{\theta}(x) \\
&P(y=0 \mid x ; \theta)=1-h_{\theta}(x)
\end{aligned}
Note that this can be written more compactly as
p(y∣x;theta)=(h_(theta)(x))^(y)(1-h_(theta)(x))^(1-y)p(y \mid x ; \theta)=\left(h_{\theta}(x)\right)^{y}\left(1-h_{\theta}(x)\right)^{1-y}
Assuming that the nn training examples were generated independently, we can then write down the likelihood of the parameters as
How do we maximize the likelihood? Similar to our derivation in the case of linear regression, we can use gradient ascent. Written in vectorial notation, our updates will therefore be given by theta:=theta+alphagrad_(theta)ℓ(theta)\theta:=\theta+\alpha \nabla_{\theta} \ell(\theta). (Note the positive rather than negative sign in the update formula, since we're maximizing, rather than minimizing, a function now.) Let's start by working with just one training example (x,y)(x, y), and take derivatives to derive the stochastic gradient ascent rule:
If we compare this to the LMS update rule, we see that it looks identical; but this is not the same algorithm, because h_(theta)(x^((i)))h_{\theta}\left(x^{(i)}\right) is now defined as a non-linear function of theta^(T)x^((i))\theta^{T} x^{(i)}. Nonetheless, it's a little surprising that we end up with the same update rule for a rather different algorithm and learning problem. Is this coincidence, or is there a deeper reason behind this? We'll answer this when we get to GLM models.
6. Digression: The perceptron learning algorithm
We now digress to talk briefly about an algorithm that's of some historical interest, and that we will also return to later when we talk about learning theory. Consider modifying the logistic regression method to "force" it to output values that are either 00 or 11 exactly. To do so, it seems natural to change the definition of gg to be the threshold function:
If we then let h_(theta)(x)=g(theta^(T)x)h_{\theta}(x)=g\left(\theta^{T} x\right) as before but using this modified definition of gg, and if we use the update rule
In the 1960s, this "perceptron" was argued to be a rough model for how individual neurons in the brain work. Given how simple the algorithm is, it will also provide a starting point for our analysis when we talk about learning theory later in this class. Note however that even though the perceptron may be cosmetically similar to the other algorithms we talked about, it is actually a very different type of algorithm than logistic regression and least squares linear regression; in particular, it is difficult to endow the perceptron's predictions with meaningful probabilistic interpretations, or derive the perceptron as a maximum likelihood estimation algorithm.
7. Another algorithm for maximizing ℓ(theta)\ell(\theta)
Returning to logistic regression with g(z)g(z) being the sigmoid function, let's now talk about a different algorithm for maximizing ℓ(theta)\ell(\theta).
To get us started, let's consider Newton's method for finding a zero of a function. Specifically, suppose we have some function f:R|->Rf: \mathbb{R} \mapsto \mathbb{R}, and we wish to find a value of theta\theta so that f(theta)=0f(\theta)=0. Here, theta inR\theta \in \mathbb{R} is a real number. Newton's method performs the following update:
This method has a natural interpretation in which we can think of it as approximating the function ff via a linear function that is tangent to ff at the current guess theta\theta, solving for where that linear function equals to zero, and letting the next guess for theta\theta be where that linear function is zero.
Here's a picture of the Newton's method in action:
In the leftmost figure, we see the function ff plotted along with the line y=0y=0. We're trying to find theta\theta so that f(theta)=0f(\theta)=0; the value of theta\theta that achieves this is about 1.31.3. Suppose we initialized the algorithm with theta=4.5\theta=4.5. Newton's method then fits a straight line tangent to ff at theta=4.5\theta=4.5, and solves for the where that line evaluates to 00. (Middle figure.) This give us the next guess for theta\theta, which is about 2.82.8. The rightmost figure shows the result of running one more iteration, which the updates theta\theta to about 1.81.8. After a few more iterations, we rapidly approach theta=1.3\theta=1.3.
Newton's method gives a way of getting to f(theta)=0f(\theta)=0. What if we want to use it to maximize some function ℓ\ell? The maxima of ℓ\ell correspond to points where its first derivative ℓ^(')(theta)\ell^{\prime}(\theta) is zero. So, by letting f(theta)=ℓ^(')(theta)f(\theta)=\ell^{\prime}(\theta), we can use the same algorithm to maximize ℓ\ell, and we obtain update rule:
(Something to think about: How would this change if we wanted to use Newton's method to minimize rather than maximize a function?)
Lastly, in our logistic regression setting, theta\theta is vector-valued, so we need to generalize Newton's method to this setting. The generalization of Newton's method to this multidimensional setting (also called the Newton-Raphson method) is given by
Here, grad_(theta)ℓ(theta)\nabla_{\theta} \ell(\theta) is, as usual, the vector of partial derivatives of ℓ(theta)\ell(\theta) with respect to the theta_(i)\theta_{i}'s; and HH is an dd-by-dd matrix (actually, d+1-by-d+1d+1-by-\mathrm{d}+1, assuming that we include the intercept term) called the Hessian, whose entries are given by
Newton's method typically enjoys faster convergence than (batch) gradient descent, and requires many fewer iterations to get very close to the minimum. One iteration of Newton's can, however, be more expensive than one iteration of gradient descent, since it requires finding and inverting an dd-by-dd Hessian; but so long as dd is not too large, it is usually much faster overall. When Newton's method is applied to maximize the logistic regression log likelihood function ℓ(theta)\ell(\theta), the resulting method is also called Fisher scoring.
So far, we've seen a regression example, and a classification example. In the regression example, we had y|x;theta∼N(mu,sigma^(2))y | x ; \theta \sim \mathcal{N}\left(\mu, \sigma^{2}\right), and in the classification one, y|x;theta∼Bernoulli(phi)y | x ; \theta \sim \operatorname{Bernoulli}(\phi), for some appropriate definitions of mu\mu and phi\phi as functions of xx and theta\theta. In this section, we will show that both of these methods are special cases of a broader family of models, called Generalized Linear Models (GLMs). We will also show how other models in the GLM family can be derived and applied to other classification and regression problems.
8. The exponential family
To work our way up to GLMs, we will begin by defining exponential family distributions. We say that a class of distributions is in the exponential family if it can be written in the form
Here, eta\eta is called the natural parameter (also called the canonical parameter) of the distribution; T(y)T(y) is the sufficient statistic (for the distributions we consider, it will often be the case that T(y)=yT(y)=y); and a(eta)a(\eta) is the log partition function. The quantity e^(-a(eta))e^{-a(\eta)} essentially plays the role of a normalization constant, that makes sure the distribution p(y;eta)p(y ; \eta) sums/integrates over yy to 11.
A fixed choice of T,aT, a and bb defines a family (or set) of distributions that is parameterized by eta\eta; as we vary eta\eta, we then get different distributions within this family.
We now show that the Bernoulli and the Gaussian distributions are examples of exponential family distributions. The Bernoulli distribution with mean phi\phi, written Bernoulli (phi)(\phi), specifies a distribution over y in{0,1}y \in\{0,1\}, so that p(y=1;phi)=phi;p(y=0;phi)=1-phip(y=1 ; \phi)=\phi ; p(y=0 ; \phi)=1-\phi. As we vary phi\phi, we obtain Bernoulli distributions with different means. We now show that this class of Bernoulli distributions, ones obtained by varying phi\phi, is in the exponential family; i.e., that there is a choice of T,aT, a and bb so that Equation (3) becomes exactly the class of Bernoulli distributions.
Thus, the natural parameter is given by eta=log(phi//(1-phi))\eta=\log (\phi /(1-\phi)). Interestingly, if we invert this definition for eta\eta by solving for phi\phi in terms of eta\eta, we obtain phi=\phi=1//(1+e^(-eta))1 /\left(1+e^{-\eta}\right). This is the familiar sigmoid function! This will come up again when we derive logistic regression as a GLM. To complete the formulation of the Bernoulli distribution as an exponential family distribution, we also have
This shows that the Bernoulli distribution can be written in the form of Equation (3), using an appropriate choice of T,aT, a and bb.
Let's now move on to consider the Gaussian distribution. Recall that, when deriving linear regression, the value of sigma^(2)\sigma^{2} had no effect on our final choice of theta\theta and h_(theta)(x)h_{\theta}(x). Thus, we can choose an arbitrary value for sigma^(2)\sigma^{2} without changing anything. To simplify the derivation below, let's set sigma^(2)=1\sigma^{2}=1.[6] We then have:
There're many other distributions that are members of the exponential family: The multinomial (which we'll see later), the Poisson (for modelling count-data; also see the problem set); the gamma and the exponential (for modelling continuous, non-negative random variables, such as timeintervals); the beta and the Dirichlet (for distributions over probabilities); and many more. In the next section, we will describe a general "recipe" for constructing models in which yy (given xx and theta\theta) comes from any of these distributions.
9. Constructing GLMs
Suppose you would like to build a model to estimate the number yy of customers arriving in your store (or number of page-views on your website) in any given hour, based on certain features xx such as store promotions, recent advertising, weather, day-of-week, etc. We know that the Poisson distribution usually gives a good model for numbers of visitors. Knowing this, how can we come up with a model for our problem? Fortunately, the Poisson is an exponential family distribution, so we can apply a Generalized Linear Model (GLM). In this section, we will we will describe a method for constructing GLM models for problems such as these.
More generally, consider a classification or regression problem where we would like to predict the value of some random variable yy as a function of xx. To derive a GLM for this problem, we will make the following three assumptions about the conditional distribution of yy given xx and about our model:
y∣x;theta∼"ExponentialFamily"(eta)y \mid x ; \theta \sim\text{ExponentialFamily}(\eta). I.e., given xx and theta\theta, the distribution of yy follows some exponential family distribution, with parameter eta\eta.
Given xx, our goal is to predict the expected value of T(y)T(y) given xx. In most of our examples, we will have T(y)=yT(y)=y, so this means we would like the prediction h(x)h(x) output by our learned hypothesis hh to satisfy h(x)=E[y∣x]h(x)=\mathrm{E}[y \mid x]. (Note that this assumption is satisfied in the choices for h_(theta)(x)h_{\theta}(x) for both logistic regression and linear regression. For instance, in logistic regression, we had h_(theta)(x)=p(y=1∣x;theta)=0*p(y=h_{\theta}(x)=p(y=1 \mid x ; \theta)=0 \cdot p(y=0∣x;theta)+1*p(y=1∣x;theta)=E[y∣x;theta].)0 \mid x ; \theta)+1 \cdot p(y=1 \mid x ; \theta)=\mathrm{E}[y \mid x ; \theta] .)
The natural parameter eta\eta and the inputs xx are related linearly: eta=theta^(T)x\eta=\theta^{T} x. (Or, if eta\eta is vector-valued, then eta_(i)=theta_(i)^(T)x\eta_{i}=\theta_{i}^{T} x.)
The third of these assumptions might seem the least well justified of the above, and it might be better thought of as a "design choice" in our recipe for designing GLMs, rather than as an assumption per se. These three assumptions/design choices will allow us to derive a very elegant class of learning algorithms, namely GLMs, that have many desirable properties such as ease of learning. Furthermore, the resulting models are often very effective for modelling different types of distributions over yy; for example, we will shortly show that both logistic regression and ordinary least squares can both be derived as GLMs.
9.1. Ordinary Least Squares
To show that ordinary least squares is a special case of the GLM family of models, consider the setting where the target variable yy (also called the response variable in GLM terminology) is continuous, and we model the conditional distribution of yy given xx as a Gaussian N(mu,sigma^(2))\mathcal{N}\left(\mu, \sigma^{2}\right). (Here, mu\mu may depend xx.) So, we let the "ExponentialFamily"(eta)\textit{ExponentialFamily}(\eta) distribution above be the Gaussian distribution. As we saw previously, in the formulation of the Gaussian as an exponential family distribution, we had mu=eta\mu=\eta. So, we have
{:[h_(theta)(x)=E[y∣x;theta]],[=mu],[=eta],[=theta^(T)x.]:}\begin{aligned}
h_{\theta}(x) &=E[y \mid x ; \theta] \\
&=\mu \\
&=\eta \\
&=\theta^{T} x .
\end{aligned}
The first equality follows from Assumption 2, above; the second equality follows from the fact that y∣x;theta∼N(mu,sigma^(2))y \mid x ; \theta \sim \mathcal{N}\left(\mu, \sigma^{2}\right), and so its expected value is given by mu\mu; the third equality follows from Assumption 1 (and our earlier derivation showing that mu=eta\mu=\eta in the formulation of the Gaussian as an exponential family distribution); and the last equality follows from Assumption 3.
9.2. Logistic Regression
We now consider logistic regression. Here we are interested in binary classification, so y in{0,1}y \in\{0,1\}. Given that yy is binary-valued, it therefore seems natural to choose the Bernoulli family of distributions to model the conditional distribution of yy given xx. In our formulation of the Bernoulli distribution as an exponential family distribution, we had phi=1//(1+e^(-eta))\phi=1 /\left(1+e^{-\eta}\right). Furthermore, note that if y|x;theta∼Bernoulli(phi)y | x ; \theta \sim \operatorname{Bernoulli}(\phi), then E[y|x;theta]=phi\mathrm{E}[y | x ; \theta]=\phi. So, following a similar derivation as the one for ordinary least squares, we get:
So, this gives us hypothesis functions of the form h_(theta)(x)=1//(1+e^(-theta^(T)x))h_{\theta}(x)=1 /\left(1+e^{-\theta^{T} x}\right). If you are previously wondering how we came up with the form of the logistic function 1//(1+e^(-z))1 /\left(1+e^{-z}\right), this gives one answer: Once we assume that yy conditioned on xx is Bernoulli, it arises as a consequence of the definition of GLMs and exponential family distributions.
To introduce a little more terminology, the function gg giving the distribution's mean as a function of the natural parameter (g(eta)=E[T(y);eta])(g(\eta)=\mathrm{E}[T(y) ; \eta]) is called the canonical response function. Its inverse, g^(-1)g^{-1}, is called the canonical link function. Thus, the canonical response function for the Gaussian family is just the identify function; and the canonical response function for the Bernoulli is the logistic function.[7]
9.3. Softmax Regression
Let's look at one more example of a GLM. Consider a classification problem in which the response variable yy can take on any one of kk values, so y iny \in{1,2,dots,k}\{1,2, \ldots, k\}. For example, rather than classifying email into the two classes spam or not-spam–which would have been a binary classification problem–we might want to classify it into three classes, such as spam, personal mail, and work-related mail. The response variable is still discrete, but can now take on more than two values. We will thus model it as distributed according to a multinomial distribution.
Let's derive a GLM for modelling this type of multinomial data. To do so, we will begin by expressing the multinomial as an exponential family distribution.
To parameterize a multinomial over kk possible outcomes, one could use kk parameters phi_(1),dots,phi_(k)\phi_{1}, \ldots, \phi_{k} specifying the probability of each of the outcomes. However, these parameters would be redundant, or more formally, they would not be independent (since knowing any k-1k-1 of the phi_(i)\phi_{i}'s uniquely determines the last one, as they must satisfy sum_(i=1)^(k)phi_(i)=1\sum_{i=1}^{k} \phi_{i}=1). So, we will instead parameterize the multinomial with only k-1k-1 parameters, phi_(1),dots,phi_(k-1)\phi_{1}, \ldots, \phi_{k-1}, where phi_(i)=p(y=i;phi)\phi_{i}=p(y=i ; \phi), and p(y=k;phi)=1-sum_(i=1)^(k-1)phi_(i)p(y=k ; \phi)=1-\sum_{i=1}^{k-1} \phi_{i}. For notational convenience, we will also let phi_(k)=1-sum_(i=1)^(k-1)phi_(i)\phi_{k}=1-\sum_{i=1}^{k-1} \phi_{i}, but we should keep in mind that this is not a parameter, and that it is fully specified by phi_(1),dots,phi_(k-1)\phi_{1}, \ldots, \phi_{k-1}.
To express the multinomial as an exponential family distribution, we will define T(y)inR^(k-1)T(y) \in \mathbb{R}^{k-1} as follows:
Unlike our previous examples, here we do not have T(y)=yT(y)=y; also, T(y)T(y) is now a k-1k-1 dimensional vector, rather than a real number. We will write (T(y))_(i)(T(y))_{i} to denote the ii-th element of the vector T(y)T(y).
We introduce one more very useful piece of notation. An indicator function 1{*}1\{\cdot\} takes on a value of 11 if its argument is true, and 00 otherwise (1{(1\{ True }=1,1{\}=1,1\{ False }=0)\}=0). For example, 1{2=3}=01\{2=3\}=0, and 1{3=1\{3=5-2}=15-2\}=1. So, we can also write the relationship between T(y)T(y) and yy as (T(y))_(i)=1{y=i}(T(y))_{i}=1\{y=i\}. (Before you continue reading, please make sure you understand why this is true!) Further, we have that E[(T(y))_(i)]=P(y=i)=phi_(i)\mathrm{E}\left[(T(y))_{i}\right]=P(y=i)=\phi_{i}.
We are now ready to show that the multinomial is a member of the exponential family. We have:
For convenience, we have also defined eta_(k)=log(phi_(k)//phi_(k))=0\eta_{k}=\log \left(\phi_{k} / \phi_{k}\right)=0. To invert the link function and derive the response function, we therefore have that
This implies that phi_(k)=1//sum_(i=1)^(k)e^(eta_(i))\phi_{k}=1 / \sum_{i=1}^{k} e^{\eta_{i}}, which can be substituted back into Equation (4) to give the response function
This function mapping from the eta\eta's to the phi\phi's is called the softmax function.
To complete our model, we use Assumption 3, given earlier, that the eta_(i)\eta_{i}'s are linearly related to the xx's. So, have eta_(i)=theta_(i)^(T)x\eta_{i}=\theta_{i}^{T} x (for i=1,dots,k-1i=1, \ldots, k-1 ), where theta_(1),dots,theta_(k-1)inR^(d+1)\theta_{1}, \ldots, \theta_{k-1} \in \mathbb{R}^{d+1} are the parameters of our model. For notational convenience, we can also define theta_(k)=0\theta_{k}=0, so that eta_(k)=theta_(k)^(T)x=0\eta_{k}=\theta_{k}^{T} x=0, as given previously. Hence, our model assumes that the conditional distribution of yy given xx is given by
This model, which applies to classification problems where y in{1,dots,k}y \in\{1, \ldots, k\}, is called softmax regression. It is a generalization of logistic regression.
In other words, our hypothesis will output the estimated probability that p(y=i∣x;theta)p(y=i \mid x ; \theta), for every value of i=1,dots,ki=1, \ldots, k. (Even though h_(theta)(x)h_{\theta}(x) as defined above is only k-1k-1 dimensional, clearly p(y=k∣x;theta)p(y=k \mid x ; \theta) can be obtained as {:1-sum_(i=1)^(k-1)phi_(i).)\left.1-\sum_{i=1}^{k-1} \phi_{i} .\right)
Lastly, let's discuss parameter fitting. Similar to our original derivation of ordinary least squares and logistic regression, if we have a training set of nn examples {(x^((i)),y^((i)));i=1,dots,n}\left\{\left(x^{(i)}, y^{(i)}\right) ; i=1, \ldots, n\right\} and would like to learn the parameters theta_(i)\theta_{i} of this model, we would begin by writing down the log-likelihood
To obtain the second line above, we used the definition for p(y∣x;theta)p(y \mid x ; \theta) given in Equation (5). We can now obtain the maximum likelihood estimate of the parameters by maximizing ℓ(theta)\ell(\theta) in terms of theta\theta, using a method such as gradient ascent or Newton's method.
This was the first lecture from Andrew Ng's CS229 course on Machine Learning. You can read the notes from the next lecture on Generative Learning Algorithms here.
We use the notation "a:=ba:=b" to denote an operation (in a computer program) in which we set the value of a variable aa to be equal to the value of bb. In other words, this operation overwrites aa with the value of bb. In contrast, we will write "a=ba=b" when we are asserting a statement of fact, that the value of aa is equal to the value of bb. ↩︎
By slowly letting the learning rate alpha\alpha decrease to zero as the algorithm runs, it is also possible to ensure that the parameters will converge to the global minimum rather than merely oscillate around the minimum. ↩︎
Note that in the above step, we are implicitly assuming that X^(T)XX^{T} X is an invertible matrix. This can be checked before calculating the inverse. If either the number of linearly independent examples is fewer than the number of features, or if the features are not linearly independent, then X^(T)XX^{T} X will not be invertible. Even in such cases, it is possible to "fix" the situation with additional techniques, which we skip here for the sake of simplicty. ↩︎
If xx is vector-valued, this is generalized to be w^((i))=exp(-(x^((i))-x)^(T)(x^((i))-x)//(2tau^(2)))w^{(i)}=\exp (-(x^{(i)}-x)^{T}(x^{(i)}-x) /(2 \tau^{2})), or w^((i))=exp(-(x^((i))-x)^(T)Sigma^(-1)(x^((i))-x)//(2tau^(2)))w^{(i)}=\exp (-(x^{(i)}-x)^{T} \Sigma^{-1}(x^{(i)}-x) /(2 \tau^{2})), for an appropriate choice of tau\tau or Sigma\Sigma. ↩︎
The presentation of the material in this section takes inspiration from Michael I. Jordan, Learning in graphical models (unpublished book draft), and also McCullagh and Nelder, Generalized Linear Models (2nd ed.). ↩︎
If we leave sigma^(2)\sigma^{2} as a variable, the Gaussian distribution can also be shown to be in the exponential family, where eta inR^(2)\eta \in \mathbb{R}^{2} is now a 22-dimension vector that depends on both mu\mu and sigma\sigma. For the purposes of GLMs, however, the sigma^(2)\sigma^{2} parameter can also be treated by considering a more general definition of the exponential family: p(y;eta,tau)=b(a,tau)exp((eta^(T)T(y)-:}p(y ; \eta, \tau)=b(a, \tau) \exp \left(\left(\eta^{T} T(y)-\right.\right.a(eta))//c(tau))a(\eta)) / c(\tau)). Here, tau\tau is called the dispersion parameter, and for the Gaussian, c(tau)=sigma^(2)c(\tau)=\sigma^{2}; but given our simplification above, we won't need the more general definition for the examples we will consider here. ↩︎
Many texts use gg to denote the link function, and g^(-1)g^{-1} to denote the response function; but the notation we're using here, inherited from the early machine learning literature, will be more consistent with the notation used in the rest of the class. ↩︎
Recommended for you
Emil Junker
Manipulative Attacks in Group Identification
Manipulative Attacks in Group Identification
This review provides an introduction to the group identification problem and gives an overview of the feasibility and computational complexity of manipulative attacks in group identification.