Heap sort

Divide-and-conquer sort: heap sort
1. heap
Heapsort is a comparison-based sorting algorithm in the field of computer, which can be regarded as an optimized implementation of selection sorting. The similarity between heap sort and selection sort is that the input array is also divided into sorted and sorted regions, and the operation of extracting the maximum value from sorted region and inserting it into sorted region is repeatedly performed, so as to continuously reduce sorted region.The difference between them lies in the way to obtain the maximum value of the sorted area. Heap sort does not waste time on linear scanning of the sorted area, but keeps the structure of the heap and only needs to complete the repair operation of the heap each time, thus greatly reducing the time to obtain the maximum value in each step[1].
2. The definition of the heap
consider the following two question.
-
Why is the structure of the heap defined this way? What are the benefits?
-
In the process of heap design, heap implementation and heap analysis, it is because of the structure characteristic or partial sequence characteristic of heap that the process can be smoothly advanced.
A binary tree is defined as a heap if it satisfies both heap structural properties and heap partial ordering properties:
- The heap structure properties are that a binary tree is either perfect, or it has only a few fewer nodes in the bottom layer than a perfect binary tree, and the bottom nodes are placed next to each other from left to right.
- The heap partial ordering property means that the heap node stores elements such that the value of the parent node is greater than the value of all the children (the size relationship between the left and right child nodes is not required).
3. Abstract maintenance of the heap
3.1 Heap of repair
According to the partial order characteristic of heap, the largest element must be located at the top of heap, which makes heap widely used in sorting, priority queue and other occasions. So we need to fix it efficiently once the largest element at the root of the heap is removed to make it a heap again.
The process of heap repair is essentially the process of heap structural characteristics and heap partial order characteristics repair
- For structural features, there is a vacancy, so it needs to be filled in.
- For partial ordering, the left and right subtrees of the heap are still a legal heap, even though the top element is removed.
The two properties are orthogonal, which allows us to focus on fixing structural properties first, and fixing partial order properties later.
- The repair of sstructure properties is very simple due to the special nature of the heap structure: since the elements at the bottom of the heap need to be arranged from left to right, we can "safely" remove the bottom right-most elements without damaging the heap structure. So the fix to the heap structure is to take the bottom rightmost element and put it at the top of the heap.
- For the repair of partial order property, we are faced with a binary tree that meets the heap structure property. Its left and right subtrees are legitimate heaps, but its root node does not meet partial order property between the left and right child nodes. To this end, we do the following:
- Compares the values of the parent node with those of the two children. Swap the larger value of the two child nodes (let's say the left node) with the parent.
- As a result of the above operation, we introduce a new root node for the left subtree, which may violate partial order, so we need to recursively repair the left subtree as described above.
Since heaps are repaired only on a strictly decreasing series of subtrees at height, the number of repairs must not exceed the height of the heap. Because of the heap structure, its height is

3.2 Heap construction: floating up
The float up process only requirescomparisons with the parent node
The heap construction process can be thought of as inserting
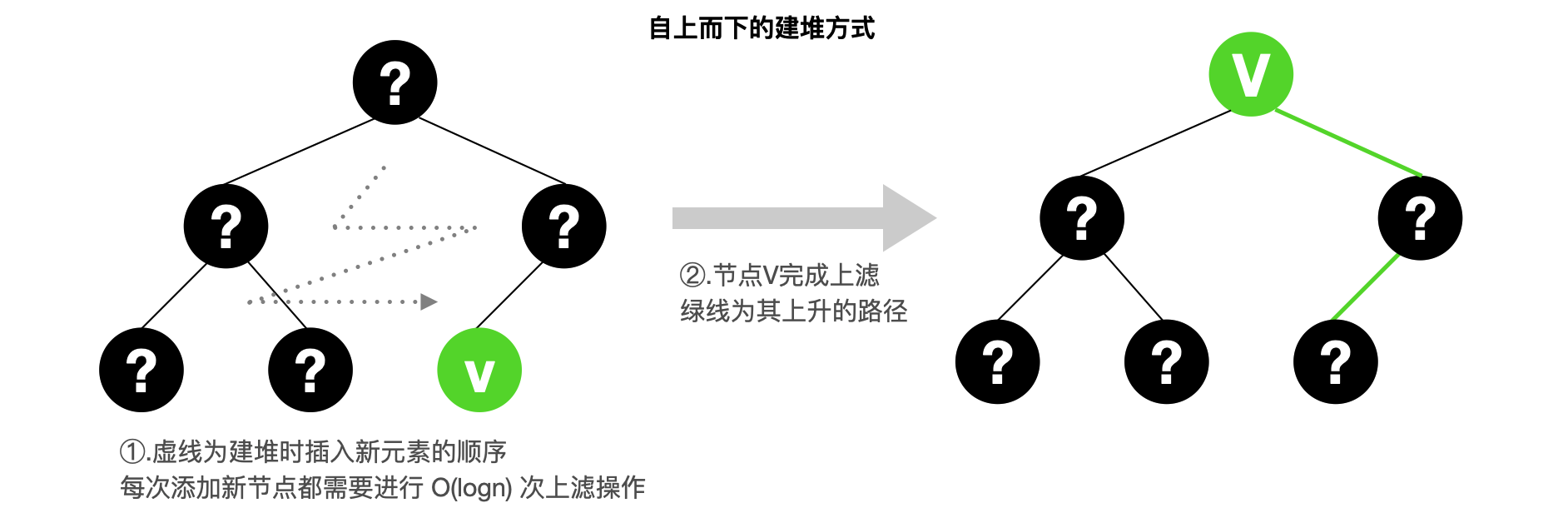
For a perfect binary tree, the points whose depth is
Although the time complexity of this heap construction is not as low as
3.3 Heap construction: sinking
The sinking process requires acomparison with the left and right child nodes
3.3.1 Algorithm implementation
It is easy to maintain a set of nodes as a binary tree that satisfies the heap structure characteristics (see discussion in 3)[2]. Suppose we have a binary tree that satisfies the heap structure, but the size relationship between the values stored by each node in the tree is chaotic. Now we need to satisfy the heap partial order between all the parent nodes in the tree. Based on the repair operation of the heap in 2.1, it is easy to construct the heap by recursion:
- Build the heap from the root.
- For the left and right subtrees of the heap structure, it is only necessary to recursively build them all into a valid heap first.

3.3.2 algorithm analysis
We can briefly analyze the complexity of heap builds based on the analysis of heap repair operations. The worst-case time complexity of sequential heap repair is
The recursive algorithm is described by the recursive equation, and the cost of the recursive algorithm is obtained by solving the recursive equation
We analyze
algorithm2 and obtain the following recursionaccording to the
This conclusion is inconsistent with the
Therefore, for a perfect binary tree, we just need to count the cost of nodes at each layer and sum up to get the total heap repair cost:
4. Concrete implementation of heap (Data structure Design)
To implement a heap, the natural place to start is with the definition of a heap. The definition of a heap has two orthogonal properties: structure property and partial order property. The partial order property is intuitively more important because it makes it easier to find the largest element. To this end, should we use a linked list structure where both parent and child nodes can access each other through Pointers? This implementation is fine for the partial ordering nature of the heap, but the main problem is that it is not easy and efficient to take an element from the bottom right for heap repair, which is very important for heap structure maintenance.
So what structures can easily maintain the structural characteristics of the heap? Let's look at another key operation, how to quickly and easily implement the parent-child node relationship?
We can place elements in a binary tree in an array in descending order of depth, and elements of the same depth from left to right.
We can identify the following mathematical properties:
( ) = ( ) = ( ) = +
The above three properties can be rigorously proved mathematically.
If
Then the serial number of its left child node is
Based on the array implementation of the heap, we can implement the repair and build operations of the heap discussed earlier.
5. summary
With the partial ordering guaranteed by the heap, it's easy to use it for sorting. The heapsort algorithm first builds all the elements into a heap. Based on the heap, the algorithm can immediately get the global largest element. Remove the largest element and place it at the end of the output sequence. For the heap with the root node removed, the algorithm performs heap repair. By repeating "root and fix" above, we can sort all the elements.
The cost of building the input
6. Optimization direction
Through the worst-case time complexity analysis of heap sort, we can know that the process of "root and repair" is the key step that affects the time complexity. The repair process is the sink process of the root node, which requires a
There is a "fact" that the "roots" taken from the bottom of the heap tend to be small, meaning that the heap can be repaired by swapping places with the larger values of the left and right child nodes. And this sinking process only requires
The "Risky" means that the node excessively sinks, resulting in a larger situation than its parent; in this case, a landing operation is required (again, only one comparison is required).
Here we can use the idea of binary search, sink to half depth, check whether the heap partial order characteristics are satisfied, if so, then sink to
7. generalization
By the extension of binary heap, we can get the definition of
We can observe the difference between binary heap and
- Binary Heap (thin and tall)
- height:
- width:
- height:
Heap (chunky) - height:
- width:
- height:
Whether binary heap or
-
Float up: the child node only needs to compare
with the parent node, and is independent of the number of children. The total cost is about , so the lower the better -
Sink operation: parent nodes need to be compared
times with child nodes, the total cost is about , so the thinner the better
Reference
- Cormen T H, Leiserson C E, Rivest R L, et al. Introduction to algorithms[M]. MIT press, 2022. ↩︎
- Schaffer R, Sedgewick R. The analysis of heapsort[J]. Journal of Algorithms, 1993, 15(1): 76-100. ↩︎
- Wegener I. Bottom-up-heap sort, a new variant of heap sort beating on average quick sort (if n is not very small)[C]//International Symposium on Mathematical Foundations of Computer Science. Springer, Berlin, Heidelberg, 1990: 516-522. ↩︎
- Carlsson S. A variant of heapsort with almost optimal number of comparisons[J]. Information Processing Letters, 1987, 24(4): 247-250. ↩︎
- Jung H. The d-deap*: A fast and simple cache-aligned d-ary deap[J]. Information processing letters, 2005, 93(2): 63-67. ↩︎
Recommended for you
Event Camera: the Next Generation of Visual Perception System
Event Camera: the Next Generation of Visual Perception System
Event camera can extend computer vision to scenarios where it is currently incompetent. In the following decades, it is hopeful that event cameras will be mature enough to be mass-produced, to have dedicated algorithms, and to show up in widely-used products.
