You can read the notes from the previous lecture from Andrew Ng's CS229 course on Kernal Methods here.
We now begin our study of deep learning. In this set of notes, we give an overview of neural networks, discuss vectorization and discuss training neural networks with backpropagation.
1. Supervised Learning with Non-linear Models
In the supervised learning setting (predicting yy from the input xx), suppose our model/hypothesis is h_(theta)(x)h_{\theta}(x). In the past lectures, we have considered the cases when h_(theta)(x)=theta^(TT)xh_{\theta}(x)=\theta^{\top} x (in linear regression or logistic regression) or h_(theta)(x)=h_{\theta}(x)=theta^(TT)phi(x)\theta^{\top} \phi(x) (where phi(x)\phi(x) is the feature map). A commonality of these two models is that they are linear in the parameters theta\theta. Next we will consider learning general family of models that are non-linear in both the parameters theta\theta and the inputs xx. The most common non-linear models are neural networks, which we will define staring from the next section. For this section, it suffices to think h_(theta)(x)h_{\theta}(x) as an abstract non-linear model.[1]
Suppose {(x^((i)),y^((i)))}_(i=1)^(n)\left\{\left(x^{(i)}, y^{(i)}\right)\right\}_{i=1}^{n} are the training examples. For simplicity, we start with the case where y^((i))inRy^{(i)} \in \mathbb{R} and h_(theta)(x)inRh_{\theta}(x) \in \mathbb{R}.
Cost/loss function. We define the least square cost function for the ii-th example (x^((i)),y^((i)))\left(x^{(i)}, y^{(i)}\right) as
which is same as in linear regression except that we introduce a constant 1//n1/n in front of the cost function to be consistent with the convention. Note that multiplying the cost function with a scalar will not change the local minima or global minima of the cost function. Also note that the underlying parameterization for h_(theta)(x)h_{\theta}(x) is different from the case of linear regression, even though the form of the cost function is the same mean-squared loss. Throughout the notes, we use the words "loss" and "cost" interchangeably.
Optimizers (SGD). Commonly, people use gradient descent (GD), stochastic gradient (SGD), or their variants to optimize the loss function J(theta)J(\theta). GD's update rule can be written as [2]
where alpha > 0\alpha>0 is often referred to as the learning rate or step size. Next, we introduce a version of the SGD (Algorithm 11), which is lightly different from that in the first lecture notes.
Algorithm 1 Stochastic Gradient Descent
1: Hyperparameter: learning rate alpha\alpha, number of total iteration n_("iter")n_{\text{iter}}.
2: Initialize theta\theta randomly.
3: fori=1i = 1 to n_("iter")n_{\text{iter}}do
4: quad\quad Sample jj uniformly from {1,dots,n}\{1,\ldots,n\}, and update theta\theta by {:(1.4)theta:=theta-alphagrad_(theta)J^(j)(theta):}\begin{equation} \theta := \theta - \alpha \nabla_{\theta}J^{j}(\theta) \tag{1.4} \end{equation}
Oftentimes computing the gradient of BB examples simultaneously for the parameter theta\theta can be faster than computing BB gradients separately due to hardware parallelization. Therefore, a mini-batch version of SGD is most commonly used in deep learning, as shown in Algorithm 22. There are also other variants of the SGD or mini-batch SGD with slightly different sampling schemes.
4: quad\quad Sample BB examples j_(1),dots,j_(B)j_{1},\ldots,j_{B} (without replacement) uniformly from {1,dots,n}\{1,\ldots, n \}, and update theta\theta by
With these generic algorithms, a typical deep learning model is learned with the following steps. 1. Define a neural network parametrization h_(theta)(x)h_{\theta}(x), which we will introduce in Section 2, and 2. write the backpropagation algorithm to compute the gradient of the loss function J^((j))(theta)J^{(j)}(\theta) efficiently, which will be covered in Section 3, and 3. run SGD or mini-batch SGD (or other gradient-based optimizers) with the loss function J(theta)J(\theta).
2. Neural Networks
Neural networks refer to broad type of non-linear models/parametrizations h_(theta)(x)h_{\theta}(x) that involve combinations of matrix multiplications and other entrywise non-linear operations. We will start small and slowly build up a neural network, step by step.
A Neural Network with a Single Neuron. Recall the housing price prediction problem from before: given the size of the house, we want to predict the price. We will use it as a running example in this subsection.
Previously, we fit a straight line to the graph of size vs. housing price. Now, instead of fitting a straight line, we wish to prevent negative housing prices by setting the absolute minimum price as zero. This produces a "kink" in the graph as shown in Figure 1. How do we represent such a function with a single kink as h_(theta)(x)h_{\theta}(x) with unknown parameter? (After doing so, we can invoke the machinery in Section 1.)
We define a parameterized function h_(theta)(x)h_{\theta}(x) with input xx, parameterized by theta\theta, which outputs the price of the house yy. Formally, h_(theta):x rarr yh_{\theta}: x \rightarrow y. Perhaps one of the simplest parametrization would be
{:(2.1)h_(theta)(x)=max(wx+b","0)", where "theta=(w","b)inR^(2):}\begin{equation}
h_{\theta}(x)=\max (w x+b, 0) \text {, where } \theta=(w, b) \in \mathbb{R}^{2}
\tag{2.1}
\end{equation}
Here h_(theta)(x)h_{\theta}(x) returns a single value: (wx+b)(w x+b) or zero, whichever is greater. In the context of neural networks, the function max{t,0}\max \{t, 0\} is called a ReLU (pronounced "ray-lu"), or rectified linear unit, and often denoted by ReLU(t)≜\operatorname{ReLU}(t) \triangleqmax{t,0}\max \{t, 0\}.
Generally, a one-dimensional non-linear function that maps R\mathbb{R} to R\mathbb{R} such as ReLU is often referred to as an activation function. The model h_(theta)(x)h_{\theta}(x) is said to have a single neuron partly because it has a single non-linear activation function. (We will discuss more about why a non-linear activation is called neuron.)
When the input x inR^(d)x \in \mathbb{R}^{d} has multiple dimensions, a neural network with a single neuron can be written as
{:(2.2)h_(theta)(x)=ReLU(w^(TT)x+b)", where "w inR^(d)","b inR", and "theta=(w","b):}\begin{equation}
h_{\theta}(x)=\operatorname{ReLU}\left(w^{\top} x+b\right) \text {, where } w \in \mathbb{R}^{d}, b \in \mathbb{R} \text {, and } \theta=(w, b)
\tag{2.2}
\end{equation}
The term bb is often referred to as the "bias", and the vector ww is referred to as the weight vector. Such a neural network has 11 layer. (We will define what multiple layers mean in the sequel.)
Stacking Neurons. A more complex neural network may take the single neuron described above and "stack" them together such that one neuron passes its output as input into the next neuron, resulting in a more complex function.
Let us now deepen the housing prediction example. In addition to the size of the house, suppose that you know the number of bedrooms, the zip code and the wealth of the neighborhood. Building neural networks is analogous to Lego bricks: you take individual bricks and stack them together to build complex structures. The same applies to neural networks: we take individual neurons and stack them together to create complex neural networks.
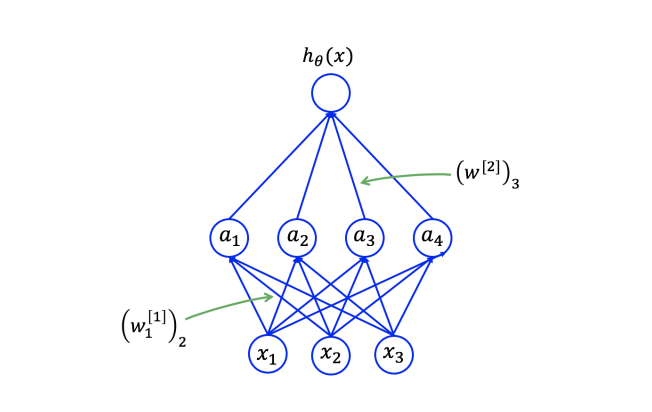
Given these features (size, number of bedrooms, zip code, and wealth), we might then decide that the price of the house depends on the maximum family size it can accommodate. Suppose the family size is a function of the size of the house and number of bedrooms (see Figure 22). The zip code may provide additional information such as how walkable the neighborhood is (i.e., can you walk to the grocery store or do you need to drive everywhere). Combining the zip code with the wealth of the neighborhood may predict the quality of the local elementary school. Given these three derived features (family size, walkable, school quality), we may conclude that the price of the home ultimately depends on these three features.
Formally, the input to a neural network is a set of input features x_(1),x_(2),x_(3),x_(4)x_{1}, x_{2}, x_{3}, x_{4}. We denote the intermediate variables for "family size", "walkable", and "school quality" by a_(1),a_(2),a_(3)a_{1}, a_{2}, a_{3} (these a_(i)a_{i}'s are often referred to as
Figure 1: Housing prices with a "kink" in the graph.
Figure 2: Diagram of a small neural network for predicting housing prices.
"hidden units" or "hidden neurons"). We represent each of the a_(i)a_{i} 's as a neural network with a single neuron with a subset of x_(1),dots,x_(4)x_{1}, \ldots, x_{4} as inputs. Then as in Figure 1, we will have the parameterization:
where (theta_(1),cdots,theta_(8))\left(\theta_{1}, \cdots, \theta_{8}\right) are parameters. Now we represent the final output h_(theta)(x)h_{\theta}(x) as another linear function with a_(1),a_(2),a_(3)a_{1}, a_{2}, a_{3} as inputs, and we get[3]
where theta\theta contains all the parameters (theta_(1),dots,theta_(12))(\theta_{1},\ldots,\theta_{12}).
Now we represent the output as a quite complex function of xx with parameters theta\theta. Then you can use this parametrization h_(theta)h_{\theta} with the machinery of Section 1 to learn the parameters theta\theta.
Inspiration from Biological Neural Networks. As the name suggests, artificial neural networks were inspired by biological neural networks. The hidden units a_(1),dots,a_(m)a_{1}, \ldots, a_{m} correspond to the neurons in a biological neural network, and the parameters theta_(i)\theta_{i}'s correspond to the synapses. However, it's unclear how similar the modern deep artificial neural networks are to the biological ones. For example, perhaps not many neuroscientists think biological neural networks could have 1000 layers, while some modern artificial neural networks do (we will elaborate more on the notion of layers.) Moreover, it's an open question whether human brains update their neural networks in a way similar to the way that computer scientists learn artificial neural networks (using backpropagation, which we will introduce in the next section.).
Two-layer Fully-Connected Neural Networks. We constructed the neural network in equation (2.3) using a significant amount of prior knowledge/belief about how the "family size", "walkable", and "school quality" are determined by the inputs. We implicitly assumed that we know the family size is an important quantity to look at and that it can be determined by only the "size" and "# bedrooms". Such a prior knowledge might not be available for other applications. It would be more flexible and general to have a generic parameterization. A simple way would be to write the intermediate variable a_(1)a_{1} as a function of all x_(1),dots,x_(4)x_{1}, \ldots, x_{4}:
{:(2.4)a_(1)=ReLU(w_(1)^(TT)x+b_(1))","" where "w_(1)inR^(4)" and "b_(1)inR:}\begin{equation}
a_{1}=\operatorname{ReLU}\left(w_{1}^{\top} x+b_{1}\right), \text { where } w_{1} \in \mathbb{R}^{4} \text { and } b_{1} \in \mathbb{R}
\tag{2.4}
\end{equation}
a_(2)=ReLU(w_(2)^(TT)x+b_(2))," where "w_(2)inR^(4)" and "b_(2)inRa_{2}=\operatorname{ReLU}\left(w_{2}^{\top} x+b_{2}\right), \text { where } w_{2} \in \mathbb{R}^{4} \text { and } b_{2} \in \mathbb{R}
a_(3)=ReLU(w_(3)^(TT)x+b_(3))," where "w_(3)inR^(4)" and "b_(3)inRa_{3}=\operatorname{ReLU}\left(w_{3}^{\top} x+b_{3}\right), \text { where } w_{3} \in \mathbb{R}^{4} \text { and } b_{3} \in \mathbb{R}
We still define h_(theta)(x)h_{\theta}(x) using equation (2.3) with a_(1),a_(2),a_(3)a_{1}, a_{2}, a_{3} being defined as above. Thus we have a so-called fully-connected neural network as visualized in the dependency graph in Figure 2 because all the intermediate variables a_(i)a_{i}'s depend on all the inputs x_(i)x_{i}'s.
For full generality, a two-layer fully-connected neural network with mm hidden units and dd dimensional input x inR^(d)x \in \mathbb{R}^{d} is defined as
Figure 3: Diagram of a two-layer fully connected neural network. Each edge from node x_(i)x_{i} to node a_(j)a_{j} indicates that a_(j)a_{j} depends on x_(i)x_{i}. The edge from x_(i)x_{i} to a_(j)a_{j} is associated with the weight (w_(j)^([1]))_(i)\left(w_{j}^{[1]}\right)_{i} which denotes the ii-th coordinate of the vector w_(j)^([1])w_{j}^{[1]}. The activation a_(j)a_{j} can be computed by taking the ReLUof the weighted sum of x_(i)x_{i} 's with the weights being the weights associated with the incoming edges, that is, a_(j)=ReLU(sum_(i=1)^(d)(w_(j)^([1]))_(i)x_(i))a_{j}=\operatorname{ReLU}\left(\sum_{i=1}^{d}\left(w_{j}^{[1]}\right)_{i} x_{i}\right).
{:[a_(j)=ReLU(z_(j))","],[a=[a_(1),dots,a_(m)]^(TT)inR^(m)],(2.6)h_(theta)(x)=w^([2]^(TT))a+b^([2])" where "w^([2])inR^(m)","b^([2])inR",":}\begin{align}
a_{j} &=\operatorname{ReLU}\left(z_{j}\right),\nonumber \\
a &=\left[a_{1}, \ldots, a_{m}\right]^{\top} \in \mathbb{R}^{m}\nonumber \\
h_{\theta}(x) &=w^{[2]^{\top}} a+b^{[2]} \text { where } w^{[2]} \in \mathbb{R}^{m}, b^{[2]} \in \mathbb{R},
\tag{2.6}
\end{align}
Note that by default the vectors in R^(d)\mathbb{R}^{d} are viewed as column vectors, and in particular aa is a column vector with components a_(1),a_(2),dots,a_(m)a_{1}, a_{2}, \ldots, a_{m}. The indices ^([1]){ }^{[1]} and ^([2]){ }^{[2]} are used to distinguish two sets of parameters: the w_(j)^([1])w_{j}^{[1]},s (each of which is a vector in R^(d)\mathbb{R}^{d} ) and w^([2])w^{[2]} (which is a vector in R^(m)\mathbb{R}^{m} ). We will have more of these later.
Vectorization. Before we introduce neural networks with more layers and more complex structures, we will simplify the expressions for neural networks with more matrix and vector notations. Another important motivation of vectorization is the speed perspective in the implementation. In order to implement a neural network efficiently, one must be careful when using for loops. The most natural way to implement equation (2.5) in code is perhaps to use a for loop. In practice, the dimensionalities of the inputs and hidden units are high. As a result, code will run very slowly if you use for loops. Leveraging the parallelism in GPUs is/was crucial for the progress of deep learning.
This gave rise to vectorization. Instead of using for loops, vectorization takes advantage of matrix algebra and highly optimized numerical linear algebra packages (e.g., BLAS) to make neural network computations run quickly. Before the deep learning era, a for loop may have been sufficient on smaller datasets, but modern deep networks and state-of-the-art datasets will be infeasible to run with for loops.
We vectorize the two-layer fully-connected neural network as below. We define a weight matrix W^([1])W^{[1]} in R^(m xx d)\mathbb{R}^{m \times d} as the concatenation of all the vectors w_(j)^([1],s)w_{j}^{[1], s} in the following way:
Now by the definition of matrix vector multiplication, we can write z=z=[z_(1),dots,z_(m)]^(TT)inR^(m)\left[z_{1}, \ldots, z_{m}\right]^{\top} \in \mathbb{R}^{m} as
We remark again that a vector in R^(d)\mathbb{R}^{d} in this notes, following the conventions previously established, is automatically viewed as a column vector, and can also be viewed as a d xx1d \times 1 dimensional matrix. (Note that this is different from numpy where a vector is viewed as a row vector in broadcasting.)
Computing the activations a inR^(m)a \in \mathbb{R}^{m} from z inR^(m)z \in \mathbb{R}^{m} involves an elementwise non-linear application of the ReLU function, which can be computed in parallel efficiently. Overloading ReLU for element-wise application of ReLU (meaning, for a vector t inR^(d)t \in \mathbb{R}^{d}, ReLU(t)\operatorname{ReLU}(t) is a vector such that ReLU(t)_(i)=\operatorname{ReLU}(t)_{i}={: ReLU(t_(i)))\left.\operatorname{ReLU}\left(t_{i}\right)\right), we have
Define W^([2])=[w^([2]^(TT))]inR^(1xx m)W^{[2]}=\left[w^{[2]^{\top}}\right] \in \mathbb{R}^{1 \times m} similarly. Then, the model in equation (2.6) can be summarized as
{:[a=ReLU(W^([1])x+b^([1]))],(2.11)h_(theta)(x)=W^([2])a+b^([2]):}\begin{align}
a &=\operatorname{ReLU}\left(W^{[1]} x+b^{[1]}\right)\nonumber \\
h_{\theta}(x) &=W^{[2]} a+b^{[2]}
\tag{2.11}
\end{align}
Here theta\theta consists of W^([1]),W^([2])W^{[1]}, W^{[2]} (often referred to as the weight matrices) and b^([1]),b^([2])b^{[1]}, b^{[2]} (referred to as the biases). The collection of W^([1]),b^([1])W^{[1]}, b^{[1]} is referred to as the first layer, and W^([2]),b^([2])W^{[2]}, b^{[2]} the second layer. The activation aa is referred to as the hidden layer. A two-layer neural network is also called one-hidden-layer neural network.
Multi-layer fully-connected neural networks. With this succinct notations, we can stack more layers to get a deeper fully-connected neural network. Let rr be the number of layers (weight matrices). Let W^([1]),dots,W^([r]),b^([1]),dots,b^([r])W^{[1]}, \ldots, W^{[r]}, b^{[1]}, \ldots, b^{[r]} be the weight matrices and biases of all the layers. Then a multi-layer neural network can be written as
We note that the weight matrices and biases need to have compatible dimensions for the equations above to make sense. If a^([k])a^{[k]} has dimension m_(k)m_{k}, then the weight matrix W^([k])W^{[k]} should be of dimension m_(k)xxm_(k-1)m_{k} \times m_{k-1}, and the bias b^([k])inR^(m_(k))b^{[k]} \in \mathbb{R}^{m_{k}}. Moreover, W^([1])inR^(m_(1)xx d)W^{[1]} \in \mathbb{R}^{m_{1} \times d} and W^([r])inR^(1xxm_(r-1))W^{[r]} \in \mathbb{R}^{1 \times m_{r-1}}.
The total number of neurons in the network is m_(1)+cdots+m_(r)m_{1}+\cdots+m_{r}, and the total number of parameters in this network is (d+1)m_(1)+(m_(1)+1)m_(2)+cdots+(d+1) m_{1}+\left(m_{1}+1\right) m_{2}+\cdots+(m_(r-1)+1)m_(r)\left(m_{r-1}+1\right) m_{r}.
Sometimes for notational consistency we also write a^([0])=xa^{[0]}=x, and a^([r])=a^{[r]}=h_(theta)(x)h_{\theta}(x). Then we have simple recursion that
Note that this would have be true for k=rk=r if there were an additional ReLU in equation (2.12), but often people like to make the last layer linear (aka without a ReLU) so that negative outputs are possible and it's easier to interpret the last layer as a linear model. (More on the interpretability at the "connection to kernel method" paragraph of this section.)
Other activation functions. The activation function ReLU can be replaced by many other non-linear function sigma(*)\sigma(\cdot) that maps R\mathbb{R} to R\mathbb{R} such as
Why do we not use the identity function for sigma(z)\sigma(z)? That is, why not use sigma(z)=z\sigma(z)=z? Assume for sake of argument that b^([1])b^{[1]} and b^([2])b^{[2]} are zeros. Suppose sigma(z)=z\sigma(z)=z, then for two-layer neural network, we have that
{:(2.16)h_(theta)(x)=W^([2])a^([1]),(2.17)=W^([2])sigma(z^([1]))" by definition ",(2.18)=W^([2])z^([1])" since "sigma(z)=z,(2.19)=W^([2])W^([1])x" from Equation "(2.8),(2.20)= tilde(W)x" where " tilde(W)=W^([2])W^([1]):}\begin{align}
h_{\theta}(x) &=W^{[2]} a^{[1]} & & \nonumber \tag{2.16}\\
&=W^{[2]} \sigma\left(z^{[1]}\right) & & \text { by definition }\nonumber \tag{2.17} \\
&=W^{[2]} z^{[1]} & & \text { since } \sigma(z)=z \nonumber \tag{2.18}\\
&=W^{[2]} W^{[1]} x & & \text { from Equation }(2.8)\nonumber \tag{2.19} \\
&=\tilde{W} x & & \text { where } \tilde{W}=W^{[2]} W^{[1]}\nonumber \tag{2.20}
\end{align}
Notice how W^([2])W^([1])W^{[2]} W^{[1]} collapsed into tilde(W)\tilde{W}.
This is because applying a linear function to another linear function will result in a linear function over the original input (i.e., you can construct a tilde(W)\tilde{W} such that {:( tilde(W))x=W^([2])W^([1])x)\left.\tilde{W} x=W^{[2]} W^{[1]} x\right). This loses much of the representational power of the neural network as often times the output we are trying to predict has a non-linear relationship with the inputs. Without non-linear activation functions, the neural network will simply perform linear regression.
Connection to the Kernel Method. In the previous lectures, we covered the concept of feature maps. Recall that the main motivation for feature maps is to represent functions that are non-linear in the input xx by theta^(TT)phi(x)\theta^{\top} \phi(x), where theta\theta are the parameters and phi(x)\phi(x), the feature map, is a handcrafted function non-linear in the raw input xx. The performance of the learning algorithms can significantly depends on the choice of the feature map phi(x)\phi(x). Oftentimes people use domain knowledge to design the feature map phi(x)\phi(x) that suits the particular applications. The process of choosing the feature maps is often referred to as feature engineering.
We can view deep learning as a way to automatically learn the right feature map (sometimes also referred to as "the representation") as follows. Suppose we denote by beta\beta the collection of the parameters in a fully-connected neural networks (equation (2.12)) except those in the last layer. Then we can abstract right a^([r-1])a^{[r-1]} as a function of the input xx and the parameters in beta:a^([r-1])=phi_(beta)(x)\beta: a^{[r-1]}=\phi_{\beta}(x). Now we can write the model as
When beta\beta is fixed, then phi_(beta)(*)\phi_{\beta}(\cdot) can viewed as a feature map, and therefore h_(theta)(x)h_{\theta}(x) is just a linear model over the features phi_(beta)(x)\phi_{\beta}(x). However, we will train the neural networks, both the parameters in beta\beta and the parameters W^([r]),b^([r])W^{[r]}, b^{[r]} are optimized, and therefore we are not learning a linear model in the feature space, but also learning a good feature map phi_(beta)(*)\phi_{\beta}(\cdot) itself so that it's possible to predict accurately with a linear model on top of the feature map. Therefore, deep learning tends to depend less on the domain knowledge of the particular applications and requires often less feature engineering. The penultimate layer a^([r-1])a^{[r-1]} is often (informally) referred to as the learned features or representations in the context of deep learning.
In the example of house price prediction, a fully-connected neural network does not need us to specify the intermediate quantity such "family size", and may automatically discover some useful features in the last penultimate layer (the activation {:a^([r-1]))\left.a^{[r-1]}\right), and use them to linearly predict the housing price. Often the feature map / representation obtained from one datasets (that is, the function phi_(beta)(*)\phi_{\beta}(\cdot) can be also useful for other datasets, which indicates they contain essential information about the data. However, oftentimes, the neural network will discover complex features which are very useful for predicting the output but may be difficult for a human to understand or interpret. This is why some people refer to neural networks as a black box, as it can be difficult to understand the features it has discovered.
3. Backpropagation
In this section, we introduce backpropgation or auto-differentiation, which computes the gradient of the loss gradJ^((j))(theta)\nabla J^{(j)}(\theta) efficiently. We will start with an informal theorem that states that as long as a real-valued function ff can be efficiently computed/evaluated by a differentiable network or circuit, then its gradient can be efficiently computed in a similar time. We will then show how to do this concretely for fully-connected neural networks.
Because the formality of the general theorem is not the main focus here, we will introduce the terms with informal definitions. By a differentiable circuit or a differentiable network, we mean a composition of a sequence of differentiable arithmetic operations (additions, subtraction, multiplication, divisions, etc) and elementary differentiable functions (ReLU, exp\exp, log\log, sin\sin, cos\cos, etc.). Let the size of the circuit be the total number of such operations and elementary functions. We assume that each of the operations and functions, and their derivatives or partial derivatives can be computed in O(1)O(1) time in the computer.
Theorem 3.1 :[backpropagation or auto-differentiation, informally stated] Suppose a differentiable circuit of size NN computes a real-valued function f:R^(ℓ)rarrRf: \mathbb{R}^{\ell} \rightarrow \mathbb{R}. Then, the gradient grad f\nabla f can be computed in time O(N)O(N), by a circuit of size O(N)O(N).[4]
We note that the loss function J^((j))(theta)J^{(j)}(\theta) for the jj-th example can be indeed computed by a sequence of operations and functions involving additions, subtraction, multiplications, and non-linear activations. Thus the theorem suggests that we should be able to compute gradJ^((j))(theta)\nabla J^{(j)}(\theta) in a similar time to that for computing J^((j))(theta)J^{(j)}(\theta) itself. This does not only apply to the fully-connected neural network introduced in Section 2, but also many other types of neural networks.
In the rest of the section, we will showcase how to compute the gradient of the loss efficiently for fully-connected neural networks using backpropagation. Even though auto-differentiation or backpropagation is implemented in all the deep learning packages such as TensorFlow and PyTorch, understanding it is very helpful for gaining insights into the workings of deep learning.
3.1. Preliminary: chain rule
We first recall the chain rule in calculus. Suppose the variable JJ depends on the variables theta_(1),dots,theta_(p)\theta_{1}, \ldots, \theta_{p} via the intermediate variables g_(1),dots,g_(k)g_{1}, \ldots, g_{k}:
Here we overload the meaning of g_(j)g_{j}'s: they denote both the intermediate variables but also the functions used to compute the intermediate variables. Then, by the chain rule, we have that AA i\forall i,
For the ease of invoking the chain rule in the following subsections in various ways, we will call JJ the output variable, g_(1),dots,g_(k)g_{1}, \ldots, g_{k} intermediate variables, and theta_(1),dots,theta_(p)\theta_{1}, \ldots, \theta_{p} the input variables in the chain rule.
3.2. Backpropagation for two-layer neural networks
Now we consider the two-layer neural network defined in equation (2.11). Our general approach is to first unpack the vectorized notation to scalar form to apply the chain rule, but as soon as we finish the derivation, we will pack the scalar equations back to a vectorized form to keep the notations succinct.
Recall the following equations are used for the computation of the loss JJ :
{:[z=W^([1])x+b^([1])],[a=ReLU(z)],[h_(theta)(x)≜o=W^([2])a+b^([2])],(3.4)J=(1)/(2)(y-o)^(2):}\begin{align}
z &=W^{[1]} x+b^{[1]} \nonumber\\
a &=\operatorname{ReLU}(z) \nonumber\\
h_{\theta}(x) \triangleq o &=W^{[2]} a+b^{[2]} \nonumber\\
J &=\frac{1}{2}(y-o)^{2}\nonumber
\tag{3.4}
\end{align}
Recall that W^([1])inR^(m xx d),W^([2])inR^(1xx m)W^{[1]} \in \mathbb{R}^{m \times d}, W^{[2]} \in \mathbb{R}^{1 \times m}, and b^([1]),z,a inR^(m)b^{[1]}, z, a \in \mathbb{R}^{m}, and o,y,b^([2])inRo, y, b^{[2]} \in \mathbb{R}. Recall that a vector in R^(d)\mathbb{R}^{d} is automatically interpreted as a column vector (like a matrix in R^(d xx1)\mathbb{R}^{d \times 1}) if need be.[5]
Computing(del J)/(delW^([2]))\frac{\partial J}{\partial W^{[2]}}. Suppose W^([2])=[W_(1)^([2]),dots,W_(m)^([2])]W^{[2]}=\left[W_{1}^{[2]}, \ldots, W_{m}^{[2]}\right]. We start by computing (del J)/(delW_(i)^([2]))\frac{\partial J}{\partial W_{i}^{[2]}} using the chain rule (3.3) with oo as the intermediate variable.
Clarification for the dimensionality of the partial derivative notation. We will use the notation (del J)/(del A)\frac{\partial J}{\partial A} frequently in the rest of the lecture notes. We note that here we only use this notation for the case when JJ is a real-valued variable,[6] but AA can be a vector or a matrix. Moreover, (del J)/(del A)\frac{\partial J}{\partial A} has the same dimensionality as AA. For example, when AA is a matrix, the (i,j)(i, j)-th entry of (del J)/(del A)\frac{\partial J}{\partial A} is equal to (del J)/(delA_(ij))\frac{\partial J}{\partial A_{i j}}. If you are familiar with the notion of total derivatives, we note that the convention for dimensionality here is different from that for total derivatives.
Computing (del J)/(delW_([1])^([1]))\frac{\partial J}{\partial W_{[1]}^{[1]}}. Next we compute (del J)/(delW^([1]))\frac{\partial J}{\partial W^{[1]}}. We first unpack the vectorized notation: let W_(ij)^([1])W_{i j}^{[1]} denote the (i,j)(i, j)-the entry of W^([1])W^{[1]}, where i in[m]i \in[m] and j in[d]j \in[d]. We compute (del J)/(delW_(ij)^([I]))\frac{\partial J}{\partial W_{i j}^{[I]}} using chain rule (3.3) with z_(i)z_{i} as the intermediate variable.
We can verify that the dimensions match: (del J)/(delW^([1]))inR^(m xx d),(del J)/(del z)inR^(m xx1)\frac{\partial J}{\partial W^{[1]}} \in \mathbb{R}^{m \times d}, \frac{\partial J}{\partial z} \in \mathbb{R}^{m \times 1} and x^(TT)inR^(1xx d)x^{\top} \in \mathbb{R}^{1 \times d}.
Abstraction: For future usage, the computations for (del J)/(delW^([1]))\frac{\partial J}{\partial W^{[1]}} and (del J)/(delW^([2]))\frac{\partial J}{\partial W^{[2]}} above can be abstractified into the following claim:
Claim 3.2: Suppose JJ is a real-valued output variable, z inR^(m)z \in \mathbb{R}^{m} is the intermediate variable, and W inR^(m xx d),u inR^(d),b inR^(m)W \in \mathbb{R}^{m \times d}, u \in \mathbb{R}^{d}, b \in \mathbb{R}^{m} are the input variables, and suppose they satisfy the following:
{:(3.8)z=Wu+b,(3.9)J=J(z):}\begin{align}
z &=W u+b \nonumber\tag{3.8}\\
J &=J(z) \nonumber\tag{3.9}
\end{align}
Then (del J)/(del W)\frac{\partial J}{\partial W} and (del J)/(del b)\frac{\partial J}{\partial b} satisfy:
Computing (del J)/(del z)\frac{\partial J}{\partial z}. Equation (3.7) tells us that to compute (del J)/(del W[1])\frac{\partial J}{\partial W[1]}, it suffices to compute (del J)/(del z)\frac{\partial J}{\partial z}, which is the goal of the next few derivations.
We invoke the chain rule with JJ as the output variable, a_(i)a_{i} as the intermediate variable, and z_(i)z_{i} as the input variable,
Vectorization and abstraction. The computation above can be summarized into:
Claim 3.3: Suppose the real-valued output variable JJ and vectors z,a inR^(m)z, a \in \mathbb{R}^{m} satisfy the following:
{:[a=sigma(z)","" where "sigma" is an element-wise activation, "z","a inR^(m)],[J=J(a)]:}\begin{aligned}
a &=\sigma(z), \text { where } \sigma \text { is an element-wise activation, } z, a \in \mathbb{R}^{m} \\
J &=J(a)
\end{aligned}
where sigma^(')(*)\sigma^{\prime}(\cdot) is the element-wise derivative of the activation function sigma\sigma, and o.\odot denotes the element-wise product of two vectors of the same dimensionality.
Computing (del J)/(del a)\frac{\partial J}{\partial a}. Now it suffices to compute (del J)/(del a)\frac{\partial J}{\partial a}. We invoke the chain rule with JJ as the output variable, oo as the intermediate variable, and a_(i)a_{i} as the input variable,
Abstraction. We now present a more general form of the computation above.
Claim 3.4: Suppose JJ is a real-valued output variable, v inR^(m)v \in \mathbb{R}^{m} is the intermediate variable, and W inR^(m xx d),u inR^(d),b inR^(m)W \in \mathbb{R}^{m \times d}, u \in \mathbb{R}^{d}, b \in \mathbb{R}^{m} are the input variables, and suppose they satisfy the following:
{:[v=Wu+b],[J=J(v)]:}\begin{aligned}
v &=W u+b \\
J &=J(v)
\end{aligned}
Summary for two-layer neural networks. Now combining the equations above, we arrive at Algorithm 3 which computes the gradients for twolayer neural networks.
3.3. Multi-layer neural networks
In this section, we will derive the backpropagation algorithms for the model defined in (2.12). With the notation a^([0])=xa^{[0]}=x, recall that we have
Therefore, it suffices to compute (del J)/(delz^(lk]))\frac{\partial J}{\partial z^{l k]}}. For simplicity, let's define delta^([k])≜(del J)/(delz^(kk))\delta^{[k]} \triangleq \frac{\partial J}{\partial z^{k k}}. We compute delta^([k])\delta^{[k]} from k=rk=r to 1 inductively. First we have that
Next for k <= r-1k \leq r-1, suppose we have computed the value of delta^([k+1])\delta^{[k+1]}, then we will compute delta^([k])\delta^{[k]}. First, using Claim 3.3, we have that
As we discussed in Section 1, in the implementation of neural networks, we will leverage the parallelism across multiple examples. This means that we will need to write the forward pass (the evaluation of the outputs) of the neural network and the backward pass (backpropagation) for multiple training examples in matrix notation.
The basic idea. The basic idea is simple. Suppose you have a training set with three examples x^((1)),x^((2)),x^((3))x^{(1)}, x^{(2)}, x^{(3)}. The first-layer activations for each example are as follows:
Note the difference between square brackets [*][\cdot], which refer to the layer number, and parenthesis (*)(\cdot), which refer to the training example number. Intuitively, one would implement this using a for loop. It turns out, we can vectorize these operations as well. First, define:
You may notice that we are attempting to add b^([1])inR^(4xx1)b^{[1]} \in \mathbb{R}^{4 \times 1} to W^([1])X inW^{[1]} X \inR^(4xx3)\mathbb{R}^{4 \times 3}. Strictly following the rules of linear algebra, this is not allowed. In practice however, this addition is performed using broadcasting. We create an intermediate tilde(b)^([1])inR^(4xx3)\tilde{b}^{[1]} \in \mathbb{R}^{4 \times 3} :
We can then perform the computation: Z^([1])=W^([1])X+ tilde(b)^([1])Z^{[1]}=W^{[1]} X+\tilde{b}^{[1]}. Often times, it is not necessary to explicitly construct tilde(b)^([1])\tilde{b}^{[1]}. By inspecting the dimensions in (4.2), you can assume b^([1])inR^(4xx1)b^{[1]} \in \mathbb{R}^{4 \times 1} is correctly broadcast to W^([1])X inR^(4xx3)W^{[1]} X \in \mathbb{R}^{4 \times 3}.
The matricization approach as above can easily generalize to multiple layers, with one subtlety though, as discussed below.
Complications/Subtlety in the Implementation. All the deep learning packages or implementations put the data points in the rows of a data matrix. (If the data point itself is a matrix or tensor, then the data are concentrated along the zero-th dimension.) However, most of the deep learning papers use a similar notation to these notes where the data points are treated as column vectors.[7] There is a simple conversion to deal with the mismatch: in the implementation, all the columns become row vectors, row vectors become column vectors, all the matrices are transposed, and the orders of the matrix multiplications are flipped. In the example above, using the row major convention, the data matrix is X inR^(3xx d)X \in \mathbb{R}^{3 \times d}, the first layer weight matrix has dimensionality d xx md \times m (instead of m xx dm \times d as in the two layer neural net section), and the bias vector b^([1])inR^(1xx m)b^{[1]} \in \mathbb{R}^{1 \times m}. The computation for the hidden activation becomes
You can read the notes from the next lecture from CS229 on Regularization and Model Selection here.
If a concrete example is helpful, perhaps think about the model h_(theta)(x)=theta_(1)^(2)x_(1)^(2)+theta_(2)^(2)x_(2)^(2)+h_{\theta}(x)=\theta_{1}^{2} x_{1}^{2}+\theta_{2}^{2} x_{2}^{2}+cdots+theta_(d)^(2)x_(d)^(2)\cdots+\theta_{d}^{2} x_{d}^{2} in this subsection, even though it's not a neural network. ↩︎
Recall that, as defined in the previous lecture notes, we use the notation "a:=ba:=b" to denote an operation (in a computer program) in which we set the value of a variable aa to be equal to the value of bb. In other words, this operation overwrites aa with the value of bb. In contrast, we will write "a=ba=b" when we are asserting a statement of fact, that the value of aa is equal to the value of bb. ↩︎
Typically, for multi-layer neural network, at the end, near the output, we don’t apply ReLU, especially when the output is not necessarily a positive number. ↩︎
We note if the output of the function ff does not depend on some of the input coordinates, then we set by default the gradient w.r.t that coordinate to zero. Setting to zero does not count towards the total runtime here in our accounting scheme. This is why when N <= ℓN \leq \ell, we can compute the gradient in O(N)O(N) time, which might be potentially even less than ℓ\ell. ↩︎
We also note that even though this is the convention in math, it’s different from the convention in numpy where an one dimensional array will be automatically interpreted as a row vector. ↩︎
There is an extension of this notation to vector or matrix variable JJ. However, in practice, it's often impractical to compute the derivatives of high-dimensional outputs. Thus, we will avoid using the notation (del J)/(del A)\frac{\partial J}{\partial A} for JJ that is not a real-valued variable. ↩︎
The instructor suspects that this is mostly because in mathematics we naturally multiply a matrix to a vector on the left hand side. ↩︎
Recommended for you
@lapostadialberto
The use of Mathpix OCR with EDICO scientific editor to help blind Students in STEM education
The use of Mathpix OCR with EDICO scientific editor to help blind Students in STEM education
In this tutorial we'll show how Mathpix OCR is helpful to instantly transpose math and science assignments both in braille and speech. We'll use the free EDICO Scientific Editor to demonstrate how a math assignment can be imported using Mathpix technology, and how it can be solved using a Refreshable Braille Display.