You can read the notes from the previous lecture from Andrew Ng's CS229 course on the Mixtures of Gaussians and the EM algorithm here.
In the previous set of notes, we talked about the EM algorithm as applied to fitting a mixture of Gaussians. In this set of notes, we give a broader view of the EM algorithm, and show how it can be applied to a large family of estimation problems with latent variables. We begin our discussion with a very useful result called Jensen's inequality
1. Jensen's inequality
Let ff be a function whose domain is the set of real numbers. Recall that ff is a convex function if f^('')(x) >= 0f^{\prime \prime}(x) \geq 0 (for all x inRx \in \mathbb{R} ). In the case of ff taking vector-valued inputs, this is generalized to the condition that its hessian HH is positive semi-definite (H >= 0)(H \geq 0). If f^('')(x) > 0f^{\prime \prime}(x)>0 for all xx, then we say ff is strictly convex (in the vector-valued case, the corresponding statement is that HH must be positive definite, written H > 0H>0). Jensen's inequality can then be stated as follows:
Theorem. Let ff be a convex function, and let XX be a random variable. Then:
Moreover, if ff is strictly convex, then E[f(X)]=f(EX)\mathrm{E}[f(X)]=f(\mathrm{E} X) holds true if and only if X=E[X]X=\mathrm{E}[X] with probability 11 (i.e., if XX is a constant).
Recall our convention of occasionally dropping the parentheses when writing expectations, so in the theorem above, f(EX)=f(E[X])f(\mathrm{E} X)=f(\mathrm{E}[X]).
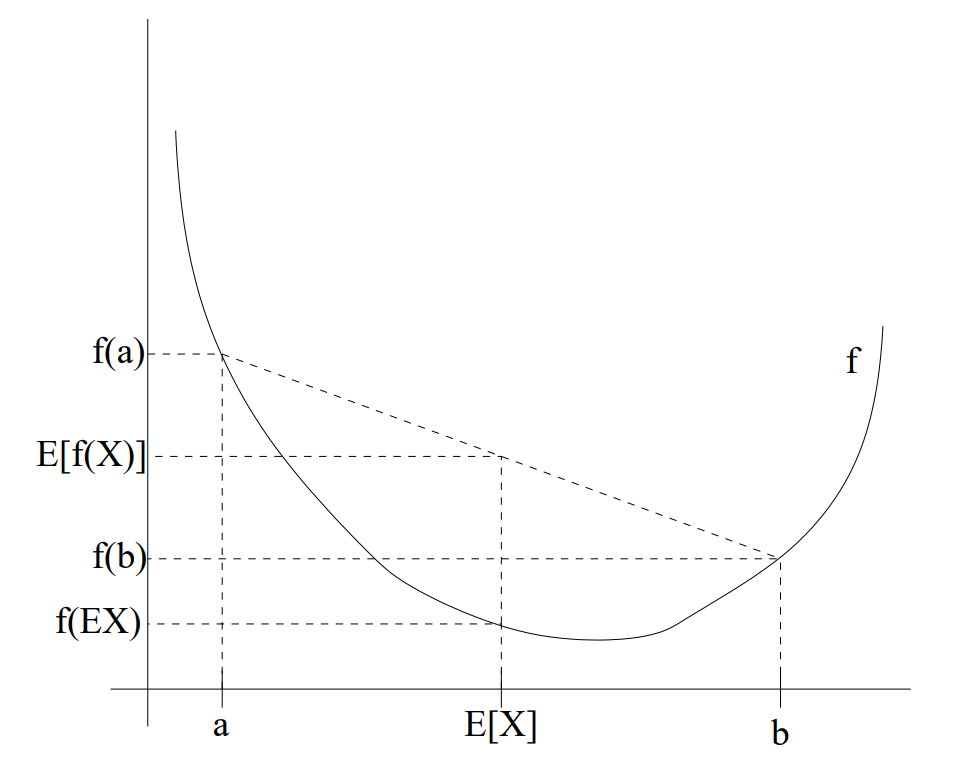
For an interpretation of the theorem, consider the figure below.
Here, ff is a convex function shown by the solid line. Also, XX is a random variable that has a 0.50.5 chance of taking the value aa, and a 0.50.5 chance of taking the value bb (indicated on the xx-axis). Thus, the expected value of XX is given by the midpoint between aa and bb.
We also see the values f(a),f(b)f(a), f(b) and f(E[X])f(\mathrm{E}[X]) indicated on the yy-axis. Moreover, the value E[f(X)]\mathrm{E}[f(X)] is now the midpoint on the yy-axis between f(a)f(a) and f(b)f(b). From our example, we see that because ff is convex, it must be the case that E[f(X)] >= f(EX)\mathrm{E}[f(X)] \geq f(\mathrm{E} X).
Incidentally, quite a lot of people have trouble remembering which way the inequality goes, and remembering a picture like this is a good way to quickly figure out the answer.
Remark. Recall that ff is [strictly] concave if and only if -f-f is [strictly] convex (i.e., f^('')(x) <= 0f^{\prime \prime}(x) \leq 0 or H <= 0H \leq 0). Jensen's inequality also holds for concave functions ff, but with the direction of all the inequalities reversed (E[f(X)] <= f(EX)\mathrm{E}[f(X)] \leq f(\mathrm{E} X), etc.).
2. The EM algorithm
Suppose we have an estimation problem in which we have a training set {x^((1)),dots,x^((n))}\left\{x^{(1)}, \ldots, x^{(n)}\right\} consisting of nn independent examples. We have a latent variable model p(x,z;theta)p(x, z ; \theta) with zz being the latent variable (which for simplicity is assumed to take finite number of values). The density for xx can be obtained by marginalized over the latent variable zz:
{:(1)p(x;theta)=sum_(z)p(x","z;theta):}\begin{equation}p(x ; \theta)=\sum_{z} p(x, z ; \theta)\end{equation}
We wish to fit the parameters theta\theta by maximizing the log-likelihood of the data, defined by
But, explicitly finding the maximum likelihood estimates of the parameters theta\theta may be hard since it will result in difficult non-convex optimization problems.[1] Here, the z^((i))z^{(i)}'s are the latent random variables; and it is often the case that if the z^((i))z^{(i)}'s were observed, then maximum likelihood estimation would be easy.
In such a setting, the EM algorithm gives an efficient method for maximum likelihood estimation. Maximizing ℓ(theta)\ell(\theta) explicitly might be difficult, and our strategy will be to instead repeatedly construct a lower-bound on ℓ\ell (E-step), and then optimize that lower-bound (M-step).[2]
It turns out that the summation sum_(i=1)^(n)\sum_{i=1}^{n} is not essential here, and towards a simpler exposition of the EM algorithm, we will first consider optimizing the the likelihood log p(x)\log p(x) for a single examplexx. After we derive the algorithm for optimizing log p(x)\log p(x), we will convert it to an algorithm that works for nn examples by adding back the sum to each of the relevant equations. Thus, now we aim to optimize log p(x;theta)\log p(x ; \theta) which can be rewritten as
The last step of this derivation used Jensen's inequality. Specifically, f(x)=log xf(x)=\log x is a concave function, since f^('')(x)=-1//x^(2) < 0f^{\prime \prime}(x)=-1 / x^{2}<0 over its domain x inR^(+)x \in \mathbb{R}^{+}. Also, the term
sum_(z)Q(z)[(p(x,z;theta))/(Q(z))]\sum_{z} Q(z)\left[\frac{p(x, z ; \theta)}{Q(z)}\right]
in the summation is just an expectation of the quantity [p(x,z;theta)//Q(z)][p(x, z ; \theta) / Q(z)] with respect to zz drawn according to the distribution given by QQ.[4] By Jensen's inequality, we have
f(E_(z∼Q)[(p(x,z;theta))/(Q(z))]) >= E_(z∼Q)[f((p(x,z;theta))/(Q(z)))],f\left(\mathrm{E}_{z \sim Q}\left[\frac{p(x, z ; \theta)}{Q(z)}\right]\right) \geq \mathrm{E}_{z \sim Q}\left[f\left(\frac{p(x, z ; \theta)}{Q(z)}\right)\right],
where the "z∼Qz \sim Q" subscripts above indicate that the expectations are with respect to zz drawn from QQ. This allowed us to go from Equation (6) to Equation (7).
Now, for any distribution QQ, the formula (7) gives a lower-bound on log p(x;theta)\log p(x ; \theta). There are many possible choices for the QQ's. Which should we choose? Well, if we have some current guess theta\theta of the parameters, it seems natural to try to make the lower-bound tight at that value of theta\theta. I.e., we will make the inequality above hold with equality at our particular value of theta\theta.
To make the bound tight for a particular value of theta\theta, we need for the step involving Jensen's inequality in our derivation above to hold with equality.
For this to be true, we know it is sufficient that the expectation be taken over a "constant"-valued random variable. I.e., we require that
(p(x,z;theta))/(Q(z))=c\frac{p(x, z ; \theta)}{Q(z)}=c
for some constant cc that does not depend on zz. This is easily accomplished by choosing
Q(z)prop p(x,z;theta).Q(z) \propto p(x, z ; \theta).
Actually, since we know sum_(z)Q(z)=1\sum_{z} Q(z)=1 (because it is a distribution), this further tells us that
{:[Q(z)=(p(x,z;theta))/(sum_(z)p(x,z;theta))],[=(p(x,z;theta))/(p(x;theta))],(8)=p(z|x;theta):}\begin{align}
Q(z) &=\frac{p(x, z ; \theta)}{\sum_{z} p(x, z ; \theta)}\nonumber \\
&=\frac{p(x, z ; \theta)}{p(x ; \theta)} \nonumber\\
&=p(z|x ; \theta)
\end{align}
Thus, we simply set the QQ's to be the posterior distribution of the zz's given xx and the setting of the parameters theta\theta.
Indeed, we can directly verify that when Q(z)=p(z|x;theta)Q(z)=p(z | x ; \theta), then equation (7) is an equality because
{:[sum_(z)Q(z)log (p(x,z;theta))/(Q(z))=sum_(z)p(z|x;theta)log (p(x,z;theta))/(p(z|x;theta))],[=sum_(z)p(z|x;theta)log (p(z|x;theta)p(x;theta))/(p(z|x;theta))],[=sum_(z)p(z|x;theta)log p(x;theta)],[=log p(x;theta)sum_(z)p(z|x;theta)],[=log p(x;theta)qquad("because "sum_(z)p(z|x;theta)=1)]:}\begin{aligned}
\sum_{z} Q(z) \log \frac{p(x, z ; \theta)}{Q(z)} &=\sum_{z} p(z | x ; \theta) \log \frac{p(x, z ; \theta)}{p(z | x ; \theta)} \\
&=\sum_{z} p(z | x ; \theta) \log \frac{p(z | x ; \theta) p(x ; \theta)}{p(z | x ; \theta)} \\
&=\sum_{z} p(z | x ; \theta) \log p(x ; \theta) \\
&=\log p(x ; \theta) \sum_{z} p(z | x ; \theta) \\
&=\log p(x ; \theta) \qquad (\text{because } \sum_{z} p(z|x ; \theta)=1)
\end{aligned}
For convenience, we call the expression in Equation (7) the evidence lower bound (ELBO) and we denote it by
{:(9)ELBO(x;Q","theta)=sum_(z)Q(z)log (p(x,z;theta))/(Q(z)):}\begin{equation}\operatorname{ELBO}(x ; Q, \theta)=\sum_{z} Q(z) \log \frac{p(x, z ; \theta)}{Q(z)}\end{equation}
With this equation, we can re-write equation (7) as
{:(10)AA Q","theta","x","quad log p(x;theta) >= ELBO(x;Q","theta):}\begin{equation}\forall Q, \theta, x, \quad \log p(x ; \theta) \geq \operatorname{ELBO}(x ; Q, \theta)\end{equation}
Intuitively, the EM algorithm alternatively updates QQ and theta\theta by a) setting Q(z)=p(z|x;theta)Q(z)=p(z | x ; \theta) following Equation (8) so that ELBO(x;Q,theta)=log p(x;theta)\operatorname{ELBO}(x ; Q, \theta)=\log p(x ; \theta) for xx and the current theta\theta, and b) maximizing ELBO(x;Q,theta)\operatorname{ELBO}(x ; Q, \theta) w.r.t theta\theta while fixing the choice of QQ.
Recall that all the discussion above was under the assumption that we aim to optimize the log-likelihood log p(x;theta)\log p(x ; \theta) for a single example xx. It turns out that with multiple training examples, the basic idea is the same and we only needs to take a sum over examples at relevant places. Next, we will build the evidence lower bound for multiple training examples and make the EM algorithm formal.
Recall we have a training set {x^((1)),dots,x^((n))}\left\{x^{(1)}, \ldots, x^{(n)}\right\}. Note that the optimal choice of QQ is p(z|x;theta)p(z | x ; \theta), and it depends on the particular example xx. Therefore here we will introduce nn distributions Q_(1),dots,Q_(n)Q_{1}, \ldots, Q_{n}, one for each example x^((i))x^{(i)}. For each example x^((i))x^{(i)}, we can build the evidence lower bound
For any set of distributions Q_(1),dots,Q_(n)Q_{1}, \ldots, Q_{n}, the formula (11) gives a lowerbound on ℓ(theta)\ell(\theta), and analogous to the argument around equation (8), the Q_(i)Q_{i} that attains equality satisfies
Thus, we simply set the Q_(i)Q_{i}'s to be the posterior distribution of the z^((i))z^{(i)}'s given x^((i))x^{(i)} with the current setting of the parameters theta\theta.
Now, for this choice of the Q_(i)Q_{i}'s, Equation (11) gives a lower-bound on the loglikelihood ℓ\ell that we're trying to maximize. This is the E-step. In the M-step of the algorithm, we then maximize our formula in Equation (11) with respect to the parameters to obtain a new setting of the theta\theta's. Repeatedly carrying out these two steps gives us the EM algorithm, which is as follows:
How do we know if this algorithm will converge? Well, suppose theta^((t))\theta^{(t)} and theta^((t+1))\theta^{(t+1)} are the parameters from two successive iterations of EM. We will now prove that ℓ(theta^((t))) <= ℓ(theta^((t+1)))\ell\left(\theta^{(t)}\right) \leq \ell\left(\theta^{(t+1)}\right), which shows EM always monotonically improves the log-likelihood. The key to showing this result lies in our choice of the Q_(i)Q_{i}'s. Specifically, on the iteration of EM in which the parameters had started out as theta^((t))\theta^{(t)}, we would have chosen Q_(i)^((t))(z^((i))):=p(z^((i))|x^((i));theta^((t)))Q_{i}^{(t)}\left(z^{(i)}\right):=p\left(z^{(i)}| x^{(i)} ; \theta^{(t)}\right). We saw earlier that this choice ensures that Jensen's inequality, as applied to get Equation (11), holds with equality, and hence
Hence, EM causes the likelihood to converge monotonically. In our description of the EM algorithm, we said we'd run it until convergence. Given the result that we just showed, one reasonable convergence test would be to check if the increase in ℓ(theta)\ell(\theta) between successive iterations is smaller than some tolerance parameter, and to declare convergence if EM is improving ℓ(theta)\ell(\theta) too slowly.
Remark. If we define (( by overloading ELBO(*))\operatorname{ELBO}(\cdot))
then we know ℓ(theta) >= ELBO(Q,theta)\ell(\theta) \geq \operatorname{ELBO}(Q, \theta) from our previous derivation. The EM can also be viewed an alternating maximization algorithm on ELBO(Q,theta)\operatorname{ELBO}(Q, \theta), in which the E-step maximizes it with respect to QQ (check this yourself), and the M-step maximizes it with respect to theta\theta.
2.1. Other interpretation of ELBO
Let ELBO(x;Q,theta)=sum_(z)Q(z)log (p(x,z;theta))/(Q(z))\operatorname{ELBO}(x ; Q, \theta)=\sum_{z} Q(z) \log \frac{p(x, z ; \theta)}{Q(z)} be defined as in equation (9). There are several other forms of ELBO. First, we can rewrite
where we use p_(z)p_{z} to denote the marginal distribution of zz (under the distribution p(x,z;theta))p(x, z ; \theta)), and D_(KL)()D_{K L}() denotes the KL divergence
In many cases, the marginal distribution of zz does not depend on the parameter theta\theta. In this case, we can see that maximizing ELBO over theta\theta is equivalent to maximizing the first term in (15). This corresponds to maximizing the conditional likelihood of xx conditioned on zz, which is often a simpler question than the original question.
Another form of ELBO(*)\operatorname{ELBO}(\cdot) is (please verify yourself)
where p_(z|x)p_{z | x} is the conditional distribution of zz given xx under the parameter theta\theta. This forms shows that the maximizer of ELBO(Q,theta)\operatorname{ELBO}(Q, \theta) over QQ is obtained when Q=p_(z|x)Q=p_{z | x}, which was shown in equation (8) before.
3. Mixture of Gaussians revisited
Armed with our general definition of the EM algorithm, let's go back to our old example of fitting the parameters phi,mu\phi, \mu and Sigma\Sigma in a mixture of Gaussians. For the sake of brevity, we carry out the derivations for the M-step updates only for phi\phi and mu_(j)\mu_{j}, and leave the updates for Sigma_(j)\Sigma_{j} as an exercise for the reader.
The E-step is easy. Following our algorithm derivation above, we simply calculate
which was what we had in the previous set of notes.
Let's do one more example, and derive the M-step update for the parameters phi_(j)\phi_{j}. Grouping together only the terms that depend on phi_(j)\phi_{j}, we find that we need to maximize
However, there is an additional constraint that the phi_(j)\phi_{j}'s sum to 11, since they represent the probabilities phi_(j)=p(z^((i))=j;phi)\phi_{j}=p\left(z^{(i)}=j ; \phi\right). To deal with the constraint that sum_(j=1)^(k)phi_(j)=1\sum_{j=1}^{k} \phi_{j}=1, we construct the Lagrangian
I.e., phi_(j)propsum_(i=1)^(n)w_(j)^((i))\phi_{j} \propto \sum_{i=1}^{n} w_{j}^{(i)}. Using the constraint that sum_(j)phi_(j)=1\sum_{j} \phi_{j}=1, we easily find that -beta=sum_(i=1)^(n)sum_(j=1)^(k)w_(j)^((i))=sum_(i=1)^(n)1=n-\beta=\sum_{i=1}^{n} \sum_{j=1}^{k} w_{j}^{(i)}=\sum_{i=1}^{n} 1=n. (This used the fact that w_(j)^((i))=Q_(i)(z^((i))=j)w_{j}^{(i)}= Q_{i}\left(z^{(i)}=j\right), and since probabilities sum to 1,sum_(j)w_(j)^((i))=11, \sum_{j} w_{j}^{(i)}=1.) We therefore have our M-step updates for the parameters phi_(j)\phi_{j}:
The derivation for the M-step updates to Sigma_(j)\Sigma_{j} are also entirely straightforward.
4. Variational inference and variational auto-encoder
Loosely speaking, variational auto-encoder [2] generally refers to a family of algorithms that extend the EM algorithms to more complex models parameterized by neural networks. It extends the technique of variational inference with the additional "re-parametrization trick" which will be introduced below. Variational auto-encoder may not give the best performance for many datasets, but it contains several central ideas about how to extend EM algorithms to high-dimensional continuous latent variables with non-linear models. Understanding it will likely give you the language and backgrounds to understand various recent papers related to it.
As a running example, we will consider the following parameterization of p(x,z;theta)p(x, z ; \theta) by a neural network. Let theta\theta be the collection of the weights of a neural network g(z;theta)g(z ; \theta) that maps z inR^(k)z \in \mathbb{R}^{k} to R^(d)\mathbb{R}^{d}. Let
{:(18)z∼N(0,I_(k xx k)),(19)x|z∼N(g(z;theta),sigma^(2)I_(d xx d)):}\begin{align}
z & \sim \mathcal{N}\left(0, I_{k \times k}\right) \\
x | z & \sim \mathcal{N}\left(g(z ; \theta), \sigma^{2} I_{d \times d}\right)
\end{align}
Here I_(k xx k)I_{k \times k} denotes identity matrix of dimension kk by kk, and sigma\sigma is a scalar that we assume to be known for simplicity.
For the Gaussian mixture models in Section 3, the optimal choice of Q(z)=p(z|x;theta)Q(z)=p(z | x ; \theta) for each fixed theta\theta, that is the posterior distribution of zz, can be analytically computed. In many more complex models such as the model (19), it's intractable to compute the exact the posterior distribution p(z|x;theta)p(z | x ; \theta).
Recall that from equation (10), ELBO is always a lower bound for any choice of QQ, and therefore, we can also aim for finding an approximation of the true posterior distribution. Often, one has to use some particular form to approximate the true posterior distribution. Let Q\mathcal{Q} be a family of QQ's that we are considering, and we will aim to find a QQ within the family of Q\mathcal{Q} that is closest to the true posterior distribution. To formalize, recall the definition of the ELBO lower bound as a function of QQ and theta\theta defined in equation (14)
Recall that EM can be viewed as alternating maximization of ELBO(Q,theta)\operatorname{ELBO}(Q, \theta). Here instead, we optimize the EBLO over Q inQQ \in \mathcal{Q}
Now the next question is what form of QQ (or what structural assumptions to make about QQ) allows us to efficiently maximize the objective above. When the latent variable zz are high-dimensional discrete variables, one popular assumption is the mean field assumption, which assumes that Q_(i)(z)Q_{i}(z) gives a distribution with independent coordinates, or in other words, Q_(i)Q_{i} can be decomposed into Q_(i)(z)=Q_(i)^(1)(z_(1))cdotsQ_(i)^(k)(z_(k))Q_{i}(z)=Q_{i}^{1}\left(z_{1}\right) \cdots Q_{i}^{k}\left(z_{k}\right). There are tremendous applications of mean field assumptions to learning generative models with discrete latent variables, and we refer to [1] for a survey of these models and their impact to a wide range of applications including computational biology, computational neuroscience, social sciences. We will not get into the details about the discrete latent variable cases, and our main focus is to deal with continuous latent variables, which requires not only mean field assumptions, but additional techniques.
When z inR^(k)z \in \mathbb{R}^{k} is a continuous latent variable, there are several decisions to make towards successfully optimizing (20). First we need to give a succinct representation of the distribution Q_(i)Q_{i} because it is over an infinite number of points. A natural choice is to assume Q_(i)Q_{i} is a Gaussian distribution with some mean and variance. We would also like to have more succinct representation of the means of Q_(i)Q_{i} of all the examples. Note that Q_(i)(z^((i)))Q_{i}\left(z^{(i)}\right) is supposed to approximate p(z^((i))|x^((i));theta)p\left(z^{(i)} | x^{(i)} ; \theta\right). It would make sense let all the means of the Q_(i)Q_{i}'s be some function of x^((i))x^{(i)}. Concretely, let q(*;phi),v(*;phi)q(\cdot ; \phi), v(\cdot ; \phi) be two functions that map from dimension dd to kk, which are parameterized by phi\phi and psi\psi, we assume that
Here diag(w)\operatorname{diag}(w) means the k xx kk \times k matrix with the entries of w inR^(k)w \in \mathbb{R}^{k} on the diagonal. In other words, the distribution Q_(i)Q_{i} is assumed to be a Gaussian distribution with independent coordinates, and the mean and standard deviations are governed by qq and vv. Often in variational auto-encoder, qq and vv are chosen to be neural networks.[6] In recent deep learning literature, often q,vq, v are called encoder (in the sense of encoding the data into latent code), whereas g(z;theta)g(z ; \theta) if often referred to as the decoder.
We remark that Q_(i)Q_{i} of such form in many cases are very far from a good approximation of the true posterior distribution. However, some approximation is necessary for feasible optimization. In fact, the form of Q_(i)Q_{i} needs to satisfy other requirements (which happened to be satisfied by the form (21))
Before optimizing the ELBO, let's first verify whether we can efficiently evaluate the value of the ELBO for fixed QQ of the form (21) and theta\theta. We rewrite the ELBO as a function of phi,psi,theta\phi, \psi, \theta by
{:(22)ELBO(phi","psi","theta)=sum_(i=1)^(n)E_(z^((i))∼Q_(i))[log (p(x^((i)),z^((i));theta))/(Q_(i)(z^((i))))],[" where "Q_(i)=N(q(x^((i));phi)","diag(v(x^((i));psi))^(2))]:}\begin{align}
\operatorname{ELBO}(\phi, \psi, \theta) &=\sum_{i=1}^{n} \mathrm{E}_{z^{(i)} \sim Q_{i}}\left[\log \frac{p\left(x^{(i)}, z^{(i)} ; \theta\right)}{Q_{i}\left(z^{(i)}\right)}\right] \\
& \text { where } Q_{i}=\mathcal{N}(q(x^{(i)} ; \phi), \operatorname{diag}(v(x^{(i)} ; \psi))^{2})\nonumber
\end{align}
Note that to evaluate Q_(i)(z^((i)))Q_{i}(z^{(i)}) inside the expectation, we should be able to compute the density ofQ_(i)Q_{i}. To estimate the expectation E_(z^((i))∼Q_(i))\mathrm{E}_{z^{(i)} \sim Q_{i}}, we should be able to sample from distributionQ_(i)Q_{i} so that we can build an empirical estimator with samples. It happens that for Gaussian distribution Q_(i)=N(q(x^((i));phi),diag(v(x^((i));psi))^(2))Q_{i}=\mathcal{N}(q(x^{(i)} ; \phi), \operatorname{diag}(v(x^{(i)} ; \psi))^{2}), we are able to be both efficiently.
Now let's optimize the ELBO. It turns out that we can run gradient ascent over phi,psi,theta\phi, \psi, \theta instead of alternating maximization. There is no strong need to compute the maximum over each variable at a much greater cost. (For Gaussian mixture model in Section 3, computing the maximum is analytically feasible and relatively cheap, and therefore we did alternating maximization.) Mathematically, let eta\eta be the learning rate, the gradient ascent step is
But computing the gradient over phi\phi and psi\psi is tricky because the sampling distribution Q_(i)Q_{i} depends on phi\phi and psi\psi. (Abstractly speaking, the issue we face can be simplified as the problem of computing the gradient E_(z∼Q_(phi))[f(phi)]\mathrm{E}_{z \sim Q_{\phi}}[f(\phi)] with respect to variable phi\phi. We know that in general, gradE_(z∼Q_(phi))[f(phi)]!=\nabla \mathrm{E}_{z \sim Q_{\phi}}[f(\phi)] \neqE_(z∼Q_(phi))[grad f(phi)]\mathrm{E}_{z \sim Q_{\phi}}[\nabla f(\phi)] because the dependency of Q_(phi)Q_{\phi} on phi\phi has to be taken into account as well.)
The idea that comes to rescue is the so-called re-parameterization trick: we rewrite z^((i))∼Q_(i)=N(q(x^((i));phi),diag (v(x^((i));psi))^(2))z^{(i)} \sim Q_{i}=\mathcal{N}\left(q\left(x^{(i)} ; \phi\right), \operatorname{diag}\left(v\left(x^{(i)} ; \psi\right)\right)^{2}\right) in an equivalent way:
{:(24)z^((i))=q(x^((i));phi)+v(x^((i));psi)o.xi^((i))" where "xi^((i))∼N(0,I_(k xx k)):}\begin{equation}z^{(i)}=q\left(x^{(i)} ; \phi\right)+v\left(x^{(i)} ; \psi\right) \odot \xi^{(i)} \text { where } \xi^{(i)} \sim \mathcal{N}\left(0, I_{k \times k}\right)\end{equation}
Here x o.yx \odot y denotes the entry-wise product of two vectors of the same dimension. Here we used the fact that x∼N(mu,sigma^(2))x \sim N\left(\mu, \sigma^{2}\right) is equivalent to that x=mu+xi sigmax=\mu+\xi \sigma with xi∼N(0,1)\xi \sim N(0,1). We mostly just used this fact in every dimension simultaneously for the random variable z^((i))∼Q_(i)z^{(i)} \sim Q_{i}.
We can now sample multiple copies of xi^((i))\xi^{(i)}'s to estimate the the expectation in the RHS of the equation above.[7] We can estimate the gradient with respect to psi\psi similarly, and with these, we can implement the gradient ascent algorithm to optimize the ELBO over phi,psi,theta\phi, \psi, \theta.
There are not many high-dimensional distributions with analytically computable density function are known to be re-parameterizable. We refer to [2] for a few other choices that can replace Gaussian distribution.
You can read the notes from the next lecture from Andrew Ng's CS229 course on Factor Analysis here.
References
[1] David M Blei, Alp Kucukelbir, and Jon D McAuliffe. Variational inference: A review for statisticians. Journal of the American Statistical Association, 112(518):859-877, 2017 .
[2] Diederik P Kingma and Max Welling. Auto-encoding variational bayes. arXiv preprint arXiv:1312.6114, 2013.
It's mostly an empirical observation that the optimization problem is difficult to optimize. ↩︎
Empirically, the E-step and M-step can often be computed more efficiently than optimizing the function ℓ(*)\ell(\cdot) directly. However, it doesn't necessarily mean that alternating the two steps can always converge to the global optimum of ℓ(*)\ell(\cdot). Even for mixture of Gaussians, the EM algorithm can either converge to a global optimum or get stuck, depending on the properties of the training data. Empirically, for real-world data, often EM can converge to a solution with relatively high likelihood (if not the optimum), and the theory behind it is still largely not understood. ↩︎
If zz were continuous, then QQ would be a density, and the summations over zz in our discussion are replaced with integrals over zz. ↩︎
We note that the notion (p(x,z;theta))/(Q(z))\frac{p(x, z ; \theta)}{Q(z)} only makes sense if Q(z)!=0Q(z) \neq 0 whenever p(x,z;theta)!=0p(x, z ; \theta) \neq 0. Here we implicitly assume that we only consider those QQ with such a property. ↩︎
We don't need to worry about the constraint that phi_(j) >= 0\phi_{j} \geq 0, because as we'll shortly see, the solution we'll find from this derivation will automatically satisfy that anyway. ↩︎
qq and vv can also share parameters. We sweep this level of details under the rug in this note. ↩︎
Empirically people sometimes just use one sample to estimate it for maximum computational efficiency. ↩︎